
Sqoop连接以及测试数据抽取
一.连接1)在自己的虚拟机上安装并配置好好 sqoop2) 启动zookeeperbin/zkServer.sh start3) 测试sqoop连接本机(虚拟机)上的mysql是否连接有效sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password Abc1234!4). 测试sqoop
·
一. 连接
1)在自己的虚拟机上安装并配置好好 sqoop
2) 启动zookeeper bin/zkServer.sh start
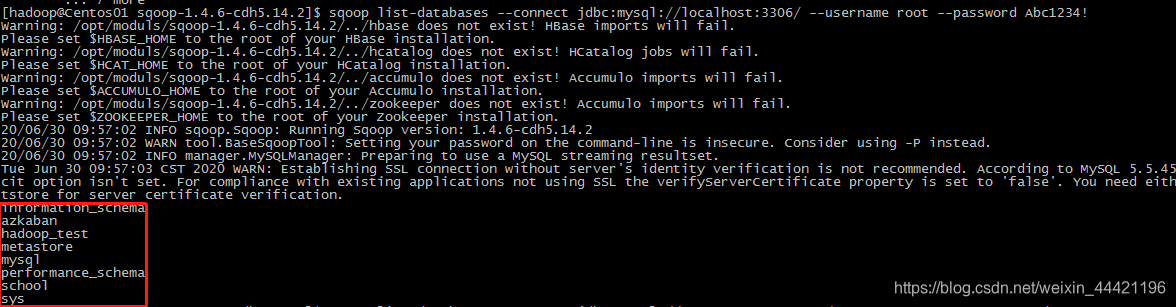
3) 测试sqoop连接本机(虚拟机)上的mysql是否连接有效
sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password Abc1234!
4). 测试sqoop连接本地机器发现报错连接不上:
sqoop list-databases --connect jdbc:mysql://192.168.50.xx:3306/ --username root --password 123456
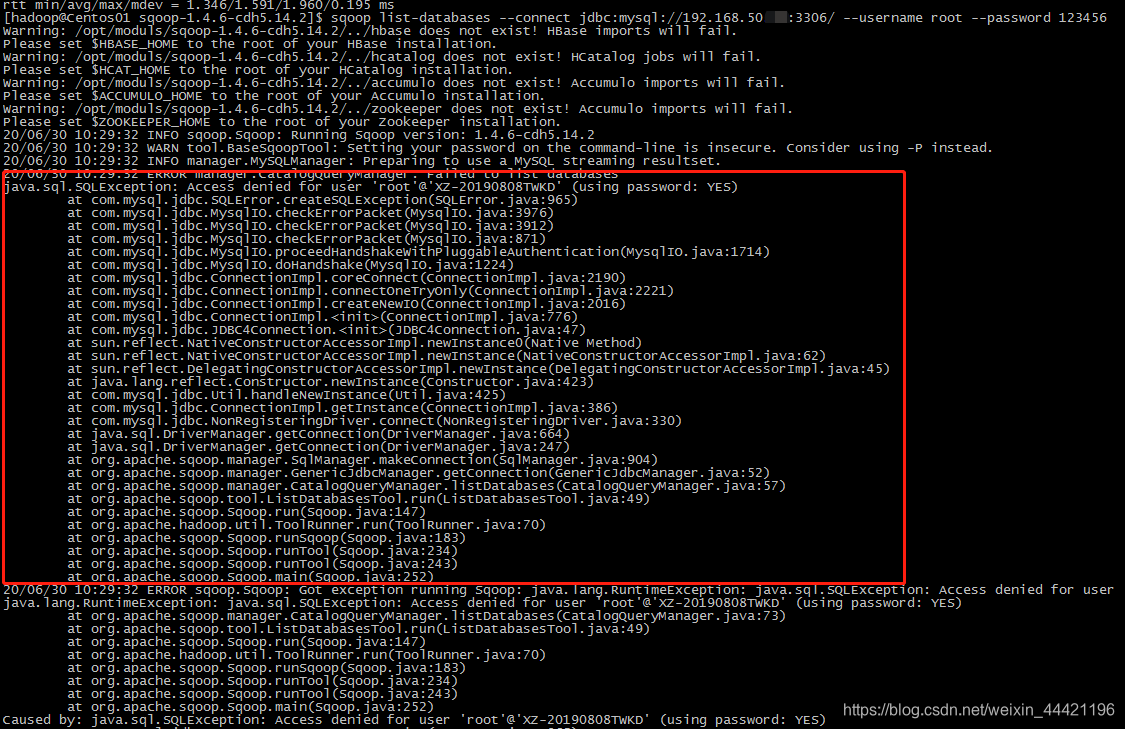
4.1)
检查虚拟机和本机是否通信有问题,互相 ping ip
如果通信没问题 ,那就检查是否mysql权限有问题,为了方便
我直接将该本地库设置为均可访问, 使用root 用户登录mysql 修改权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
退出尝试重新连接本地库:
执行:sqoop list-databases --connect jdbc:mysql://192.168.50.xx:3306/ --username root --password 123456
成功连接!
二. 数据抽取:
写一个简单的数据抽取
sqoop import \
--connect jdbc:mysql://192.168.50.xx:3306/wanwangtest \
--username root \
--password 123456 \
--target-dir /user/hive/warehouse/hive_test.db/sqoop_course \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select cno,cname,tno from course where $CONDITIONS' \
运行没有问题!
需要注意的是 --delete-target-dir 参数加入,就会删除该数据信息(内部表),当加入数据之后,直接查表名是查不到的,但是在hdfs上是可以看到目录的,因此需要执行一次创建ddl语句才能 使用select查看表信息。
解释参数:
- import : sqoop的导入命令 ,是指从外部进入到大数据集群
- export : 大数据集群导出
- –connect : 连接关系型数据库的url地址
- –username :数据库用户名
- –password : 数据库密码
- –driver : jdbc 的 driver class
- –table: 指定关系型数据库的表名
- –num-mappers :启动N个map来并行导入数据,默认是4个
- –target-dir :指定hdfs的路径
10.–compress:指定压缩参数:压缩参数,默认情况下数据是没被压缩的,通过该参数可以使用gzip压缩算法对数据进行压缩,适用于SequenceFile, text文本文件, 和Avro文件

无需安装部署,在线快速体验 Byzer
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)