
MySQL索引实现原理分析
目前大部分数据库系统及文件系统都采用B-Tree(B树)或其变种B+Tree(B+树)作为索引结构。B+Tree是数据库系统实现索引的首选数据结构。在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。MyISAM索引实现MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的...
目前大部分数据库系统及文件系统都采用B-Tree(B树)或其变种B+Tree(B+树)作为索引结构。B+Tree是数据库系统实现索引的首选数据结构。在 MySQL 中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论 MyISAM 和 InnoDB 两个存储引擎的索引实现方式。
MyISAM 索引实现
MyISAM 是非聚集索引,索引和数据文件是分离的;使用 B+Tree 作为索引结构,,索引叶节点的 data 域存放的是数据记录的地址;主键索引和辅助索引是独立的。
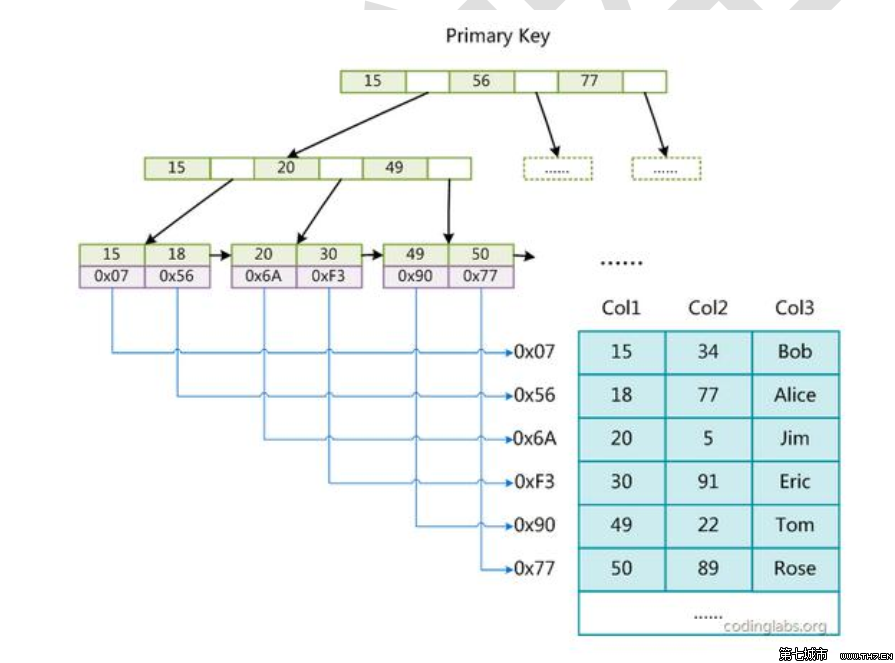
主键索引
这里设表一共有三列,假设我们以 Col1 为主键,则图是一个 MyISAM 表的主索引(Primary key)示意。可以看出 MyISAM 的索引文件叶节点仅仅保存数据记录的地址。
辅助索引
在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示。
同样也是一颗 B+Tree,data 域保存数据记录的地址。因此,MyISAM 中索引检索的算法为首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其data 域的值,然后以 data 域的值为地址,读取相应数据记录。
InnoDB 索引实现
虽然 InnoDB 也使用 B+Tree 作为索引结构,但具体实现方式却与 MyISAM 截然不同。
1、第一个重大区别是 InnoDB 的数据文件本身就是索引文件。从上文知道,MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶点data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。

上图是 InnoDB 主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集。
2、InnoDB 要求表必须有主键(MyISAM 可以没有),如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
同时,请尽量在 InnoDB 上采用自增字段做表的主键。因为 InnoDB 数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
3、还有与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说,InnoDB 的所有辅助索引都引用主键作为 data 域。
例如,下图为定义在 Col3 上的一个辅助索引:
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引(回表):首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
问:为什么不建议使用过长的字段作为主键?
答:因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
聚簇索引与非聚簇索引
InnoDB 使用的是聚簇索引, 将主键组织到一棵 B+树中, 而行数据就储存在叶子节点上, 若使用"where id = 14"这样的条件查找主键, 则按照 B+树的检索算法即可查找到对应的叶节点, 之后获得行数据。 若对 Name 列进行条件搜索, 则需要两个步骤:
第一步在辅助索引 B+树中检索 Name, 到达其叶子节点获取对应的主键。
第二步使用主键在主索引 B+树种再执行一次 B+树检索操作, 最终到达叶子节点即可获取整行数据。
MyISM 使用的是非聚簇索引, 非聚簇索引的两棵 B+树看上去没什么不同, 节点的结构完全一致只是存储的内容不同而已, 主键索引 B+树的节点存储了主键, 辅助键索引B+树存储了辅助键。 表数据存储在独立的地方, 这两颗 B+树的叶子节点都使用一个地址指向真正的表数据, 对于表数据来说, 这两个键没有任何差别。 由于索引树是独立的, 通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别, 我们假想一个表如下图存储了 3 行数据。 其中Id 作为主索引, Name 作为辅助索引。 图示清晰的显示了聚簇索引和非聚簇索引的差异:
联合索引及最左原则
联合索引存储数据结构图:

最左原则:
例如联合索引有三个索引字段(A,B,C)
查询条件:
(A,,)--- 会使用索引
(A,B,)--- 会使用索引
(A,B,C)--- 会使用索引
(,B,C)--- 不会使用索引
(,,C)--- 不会使用索引
最后来一个问题:mysql假设一行数据大小为1k,则一颗层高为3的b+树可以存放多少条数据?
mysql页默认大小16k,如果数据行大小1k,叶子节点存放的完整数据,则叶子节点一页可以放16条数据;非叶子节点页面存放的是主键和指针,所以主要看主键是啥类型,假设是integer,则长度8字节,指针大小在innodb是6字节,一共14字节,所以非叶子节点每页可以存16384/14=1170个主键数据(1170个分叉),则三层b+树数据可以存1170*1170*16=21902400条数据。(千万级别)

无需安装部署,在线快速体验 Byzer
更多推荐


 116
116 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)