
Byzer SQL 和 Byzer Data+AI 数据库
背景 多年以来,SQL 一直在各路 solo。 什么计算机语言适合入门数据行业、交互快、用途广、可扩展性好?答案总是 SQL。 只有 SQL 开发者才能看得懂的笑话 一个 SQL 查询走进了一个酒吧,看到两张 Table,它和两张 Table 说,“我能 Join 你们吗?”有人会问,也许近些年 Py
背景
多年以来,SQL 一直在各路 solo 。 什么计算机语言适合入门数据行业、交互快、用途广、可扩展性好?答案总是 SQL。

有人会问,也许近些年 Python 的流行可以挑战一下 SQL 的地位?
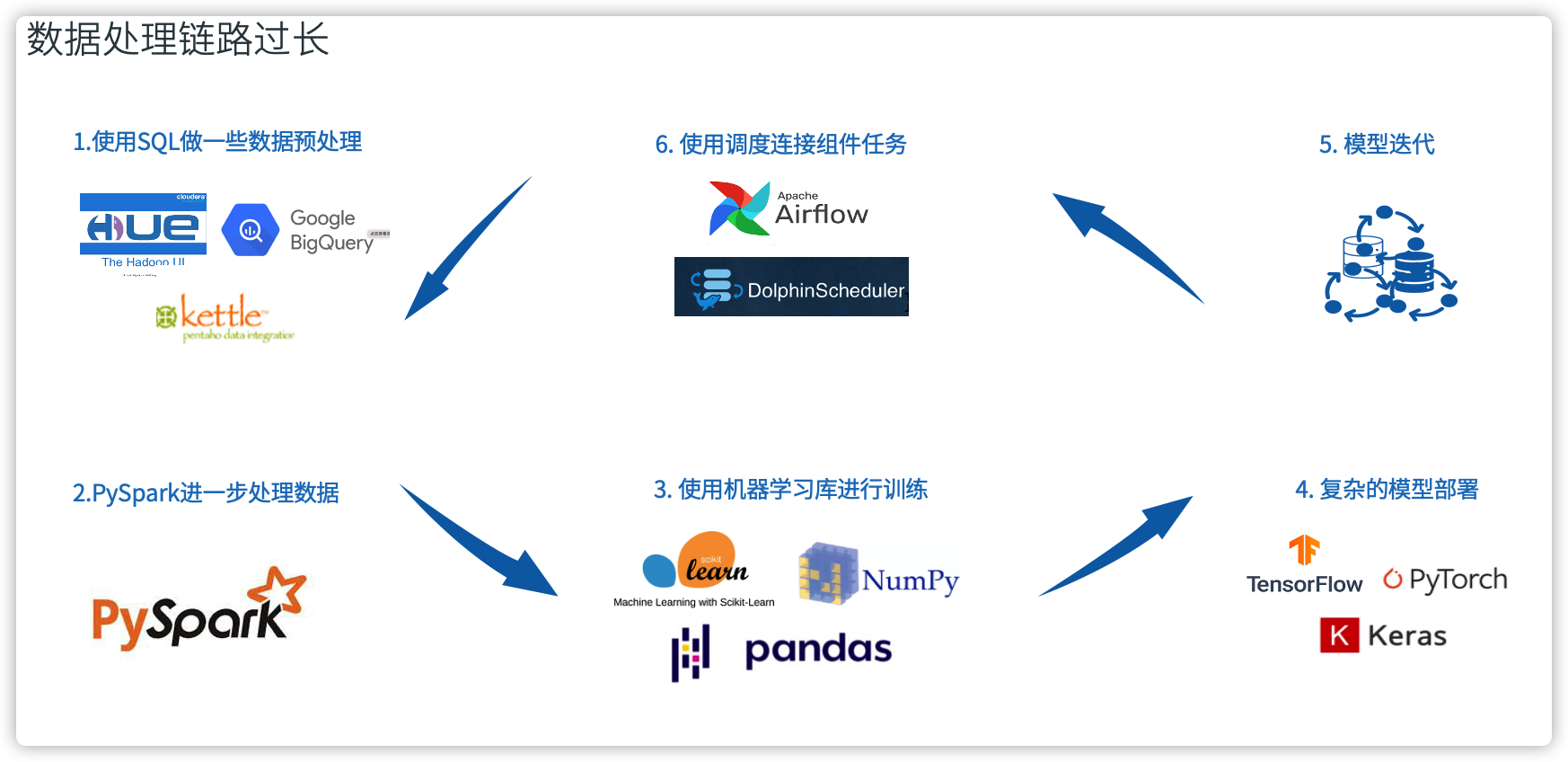
但是对于 Python 初学者,你可能需要解决大部分你不需要解决的问题。大部分非计算机专业的同学核心要解决的是数据操作问题,但是在操作数据前,你必须要学习诸如变量,函数,线程,分布式等等各种仅仅和语言自身相关的特性,这需要相当的学习成本。操作数据当然也可以使用 Excel、SAS、Alteryx(以及类似的软件),但是 Excel 有它的限制,譬如有很多较为复杂的逻辑不太好做,无法跨数据源关联,数据规模也有限。在各种对比之下,SQL 最终以其低门槛、易用性、可拓展性依然胜出。
但是SQL也它的短板,首先他最早为了关系型数据库设计的,适合查询而非 ETL,但是现在人们慢慢把他扩展到 ETL,流式处理,甚至 AI 上,它就有点吃力了。 第二个问题是,他是声明式的,导致缺乏可编程性。
那么 SQL 也不行的话,人们期望实现 Data + AI 能够统一编程的语言在哪里呢?
为了通过编程语言进行革新,从根本上提高数据平台落地和 AI 工程化的效率,Byzer SQL语言诞生了。
Byzer SQL 是什么
Byzer SQL是一门全新的编程语言,完全开源,低代码,使用 Byzer 可以实现数据处理、数据分析和 AI。
我们使用一种语言 Byzer SQL,就可以在单一平台上实现过去要使用多语言、多平台、多组件才能实现的事情。
Byzer SQL 既保留了 SQL 的所有原有优势,简洁易懂,上手就可以干活;Byzer SQL 还允许用户进阶操作,提供更多可编程能力。Byzer SQL 有以下 四大特性:

Byzer SQL 使用场景/人群
在 Byzer 中可以实现使用统一的交互语言,在一个统一的平台内即可完成 数据处理 +数据分析+数据科学 的任务。
设想一下,如果企业内的一名业务人员,通过学习进阶版的 SQL 语言 Byzer,就能够完成原来数据团队内的数据科学家 + 数据工程师 + 数据分析师的工作,那么企业在数据团队的投入成本就会大大减少。企业数字化转型不是重金招募更多数据专家,而是让每一个人都成为数据专家。

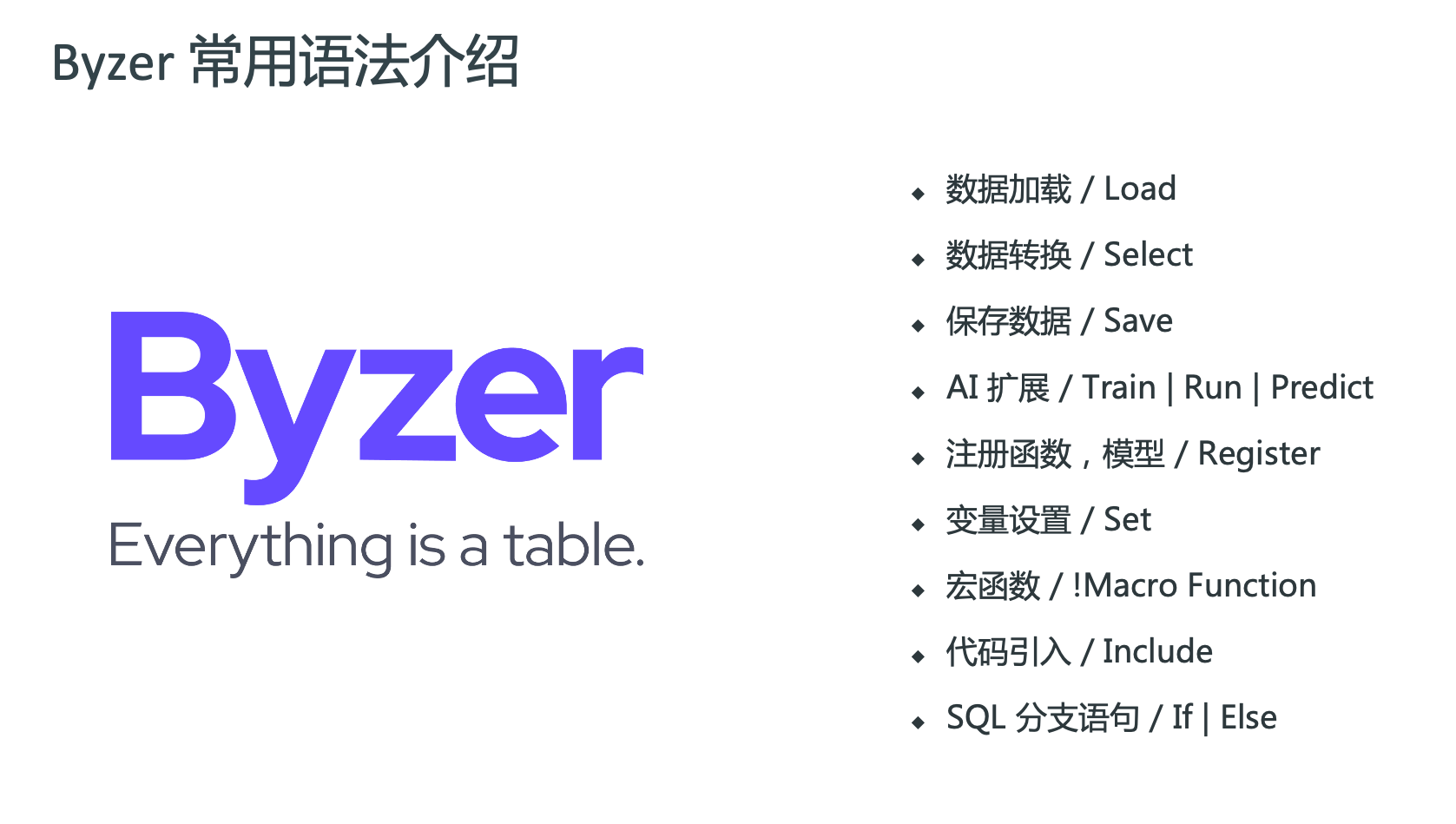
Byzer SQL 基础语法
Byzer SQL 语法非常简单,比标准的 SQL 只多了一些关键字,整个学习过程可以在几个小时内完成。在学习 SQL 的基础上,大家再多努力一点点,就可以掌握用 声明式语法 进行机器学习。
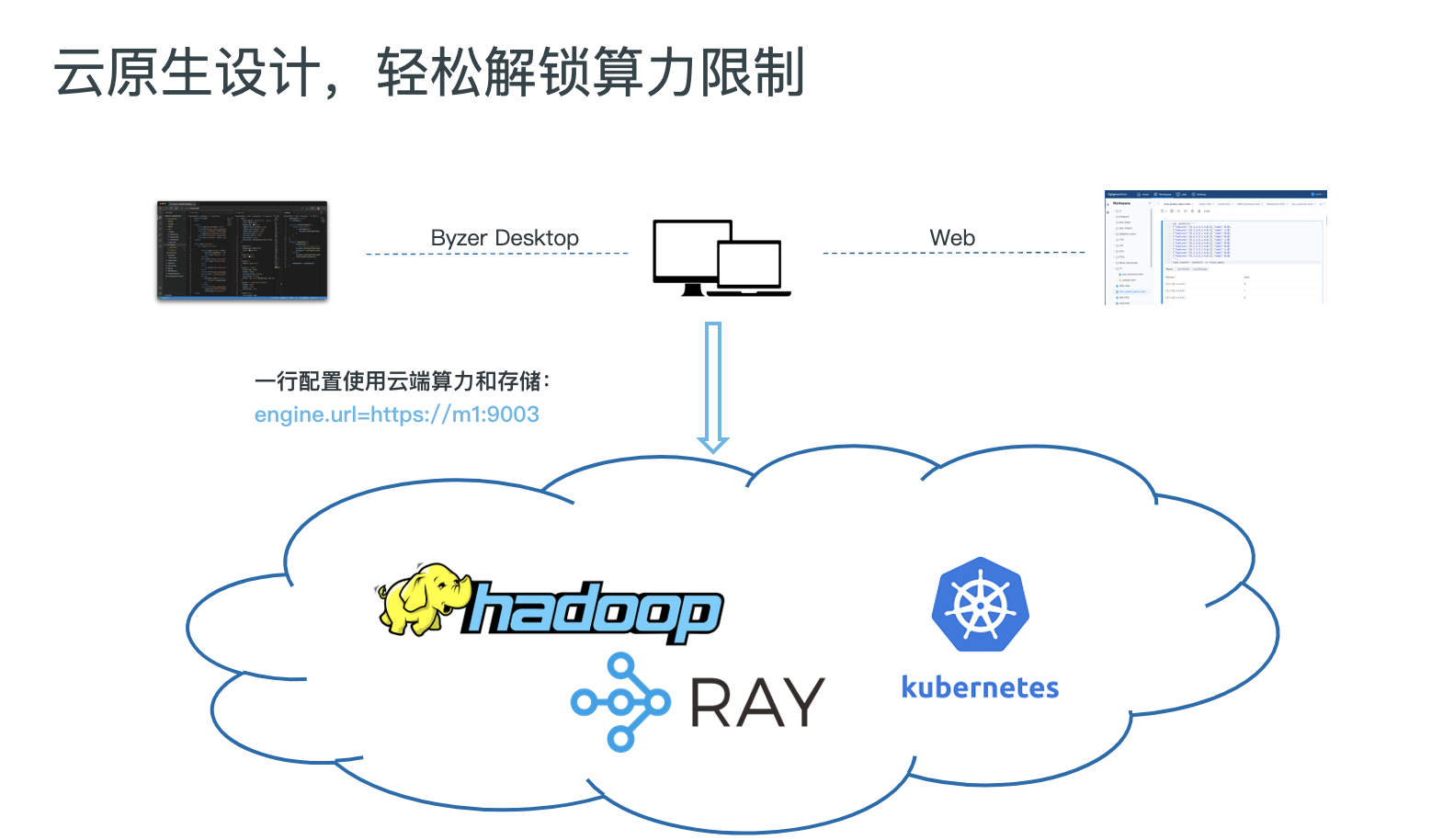
Byzer 分布式数据库
Byzer SQL 和其执行引擎构成的分布式数据库,基于云原生架构设计,用户可以使用桌面版软件,连接到云端引擎,轻松解锁算力和存储空间限制。
Byzer 数据库轻松涵盖大数据, AI 和大模型全生命周期工作。 用户使用 Byzer SQL 和 Byzer 数据库进行交互。此外, Byzer 数据库除了有 Byzer-LLM 这个大模型插件引擎以外,还有 Byzer-QARetriever 插件引擎用于基于大模型的问答检索。
Byzer 支持 Python
对于一些资深的机器学习用户,他们可能会担心,已经在其他产品例如 Jupyter Notebook 用 Python 的 scikit-learn 或者 tensorflow 进行了机器学习的模型开发,项目文件已经存在大量的代码,如何迁移到 Byzer 呢?
在 Byzer 中我们通过 插件引擎 Byzer-python 来实现对 Python 代码的引用和适配,资深 Python 用户可以继续使用您习惯的机器学习的包进行模型开发。这部分的内容可以参考 Python 扩展 章节。
更强大之处在于,Byzer-python 提供过了非常方便的 API 给用户让用户无需担心权限即可访问 Byzer 脚本中的一个或者多个视图数据,并且产生一个或者多个新的视图,不止步于此,
Byzer-python 还提供了分布式编程能力以及硬件感知能力(如 GPU), 用户可以轻易实现诸如 Parameter Server 结构的机器学习训练模式。
接下来,就上手试试 Byzer 数据库吧。

无需安装部署,在线快速体验 Byzer
更多推荐
 0
0 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)