
Tensorflow+CNN实现车牌识别
文章目录0、前言1、车牌定位1.1、训练分类器1.2、车牌粗定位1.3、倾斜矫正1.3.1、计算车牌的倾斜角1.3.2、旋转1.4、车牌精定位2、CNN训练2.2、构建CNN网络2.3、执行训练3、车牌识别3.1、读取1.4中精定位获取的图片3.2、使用CNN训练模型对精定位图片进行识别4、Mysql存储0、前言之前写过一篇基于字符切割的车牌识别博客,当时也成功做出来了,但是识别率不高,而且对..
文章目录
0、前言
之前写过一篇基于字符切割的车牌识别博客,当时也成功做出来了,但是识别率不高,而且对图片要求苛刻,例如不能大角度倾斜,不能反光,不能太模糊等。有很多原因导致当时的方法不能有效且准确的识别车牌。为了提高识别率,有在网上参考了很多前辈的算法及实现过程。期间也化了不少时间,不过最终的识别效果还是挺高的。
本项目使用的资源如下
云服务器:VAST
数据集:CCPD数据集,正样本约20w张,负样本约3w张
https://github.com/detectRecog/CCPD
语言:python3
IDE:PyCharm
python依赖包:
-
Numpy
-
OpenCV
-
PIL
-
Tensorflow
1、车牌定位
1.1、训练分类器
其实在最开始准备正样本阶段,要做的第一步是标记车牌,就是从一张图片里边crop出车牌的位置。由于机器学习模型训练都需要大量的训练集,所以对于标记车牌,要不手动,要不掏钱。不过好的一点是找到了一个已经标记好的数据集。该数据集中图片的文件名包含了很多图片信息,在此就不介绍了,github上已经说明清楚。
第一步:将CCPD中的车牌从数据集中crop出来
import cv2
import hashlib
import os,sys
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
if not os.path.exists("output"):
os.mkdir("output")
h = 40
w = 250
path = r"F:\ccpd_dataset\ccpd_base" # 根据自己的实际情况
fi = open("label.txt","w",encoding="utf-8")
for img_name in os.listdir(path):
# 读取图片的完整名字
image = cv2.imread(path + "/" + img_name)
# 以 - 为分隔符,将图片名切分,其中iname[4]为车牌字符,iname[2]为车牌坐标
iname = img_name.rsplit('/', 1)[-1].rsplit('.', 1)[0].split('-')
tempName = iname[4].split("_")
name = provinces[int(tempName[0])] + alphabets[int(tempName[1])] + ads[int(tempName[2])] \
+ ads[int(tempName[3])] + ads[int(tempName[4])] + ads[int(tempName[5])] + ads[int(tempName[6])]
# crop车牌的左上角和右下角坐标
[leftUp, rightDown] = [[int(eel) for eel in el.split('&')] for el in iname[2].split('_')]
# crop图片
img = image[leftUp[1]:rightDown[1],leftUp[0]:rightDown[0]]
height, width, depth = img.shape
# 要将图片压缩成40*250,计算压缩比
imgScale = h/height
deltaD = int((w/imgScale-width)/2) # (目标宽-实际宽)/2,因为要分别向左、右拓宽,所有需要除以2
leftUp[0] = leftUp[0] - deltaD # 切割宽度向左平移,保证补够250
rightDown[0] = rightDown[0] + deltaD # 切割宽度向右平移,保证补够250
if(leftUp[0] < 0): # 如果向左平移为负,坐标为0
rightDown[0] = rightDown[0] - leftUp[0]
leftUp[0] = 0;
# 按照 高/宽 = 40 / 250 的比例切割,注意切的结果不是40和250
img = image[leftUp[1]:rightDown[1],leftUp[0]:rightDown[0]]
# resize成40*250
newimg = cv2.resize(img,(w,h))
cv2.imwrite("output/" + img_name, newimg)
fi.write(img_name + ":" + name +"\r\n")
fi.close()
第二步:接下来就是把正负样本放置在对应的文件夹中,正样本要求图片大小一致,负样本可以随心
第三步:在当前目录下我们还得到了pos_image.txt文件和neg_image.txt文件。其中pos_image.txt文件内容格式
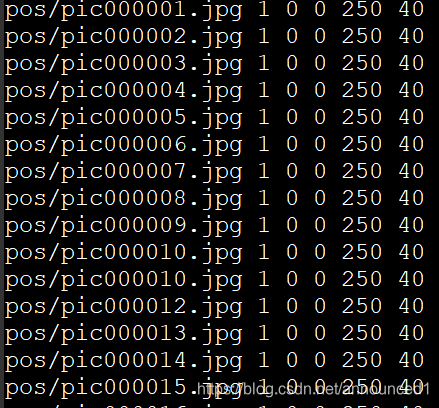
imag/pic00xxxx.jpg表示图片名字,1 0 0 分别表示图片中车牌的数量、起始坐标(x,y),图片宽高(w,h)
负样本neg_image.txt格式
第三步:使用opencv的opencv_createsamples.exe生成正样本vec文件
!opencv\build\x64\vc14\bin\opencv_createsamples.exe -vec pos.vec -info pos_image.txt -bg neg_image.txt -w 250 -h 40 -num 199998
用opencv_traincascade.exe训练级联分类器
opencv_traincascade.exe -data xml -vec pos.vec -bg neg_image.txt -numPos 16000 -numNeg 3036 -numStages 12 -precalcValBufSize 5000 -precalcIdxBufSize 5000 -w 250 -h 40 -maxWeakCount 200 -mode ALL -minHitRate 0.990 -maxFalseAlarmRate 0.20
训练完成后会在xml目录下生成一个cascade.xml文件,该文件就是训练的的级联分类器数据,我们利用它就可以识别出车牌。
1.2、车牌粗定位
使用上一目训练出的分类器进行车牌粗定位
image = cv.imread('1.png') ## 读取图片
image = cv.GaussianBlur(image , (3,3) , 0) ## 高斯去噪
resize_h = image.shape[0]
resize_w = int( image.shape[1] / image.shape[0] * resize_h)
image = cv.resize(image , (resize_w,resize_h)) ## 将原图resize
image_gray = cv.cvtColor(image,cv.COLOR_BGR2GRAY) ## 转换成灰度图
clf = cv.CascadeClassifier('./cascade.xml') ## 导入分类器
area = clf.detectMultiScale(image_gray) ## 检测车牌,可能不止一张
image2 = image.copy()
for (x,y,w,h) in area:
x -= w * 0.14
w += w * 0.28
y -= h * 0.15
h += h * 0.3
cropped_images = image2[int(x):int(x+w), int(y):int(y+h)]
return cropped_images
1.3、倾斜矫正
如果车牌倾斜没有矫正,那么水平投影和垂直投影,甚至铆钉都无法正常处理。所以,当车辆信息中获取车牌的第一步,应该是检查倾斜角度,做倾斜矫正。
1.3.1、计算车牌的倾斜角
使用基于方向场的算法检测车牌的倾角
def skew_detection(image_gray):
h, w = image_gray.shape[:2]
## cornerEigenValsAndVecs()计算图像块的特征值和特征向量用于角点检测
eigen = cv2.cornerEigenValsAndVecs(image_gray,12, 5)
angle_sur = np.zeros(180,np.uint);
eigen = eigen.reshape(h, w, 3, 2)
flow = eigen[:,:,2]
vis = image_gray.copy()
vis[:] = (192 + np.uint32(vis)) / 2
d = 12
points = np.dstack( np.mgrid[d/2:w:d, d/2:h:d] ).reshape(-1, 2)
for x, y in points:
x = int(x)
y = int(y)
vx, vy = np.int32(flow[y, x]*d)
# cv2.line(rgb, (x-vx, y-vy), (x+vx, y+vy), (0, 355, 0), 1, cv2.LINE_AA)
ang = angle(vx,vy);
angle_sur[(ang+180)%180] +=1;
# torr_bin = 30
angle_sur = angle_sur.astype(np.float)
angle_sur = (angle_sur-angle_sur.min())/(angle_sur.max()-angle_sur.min())
angle_sur = filters.gaussian_filter1d(angle_sur,5)
skew_v_val = angle_sur[20:180-20].max();
skew_v = angle_sur[30:180-30].argmax() + 30;
skew_h_A = angle_sur[0:30].max()
skew_h_B = angle_sur[150:180].max()
skew_h = 0;
if (skew_h_A > skew_v_val*0.3 or skew_h_B > skew_v_val*0.3):
if skew_h_A>=skew_h_B:
skew_h = angle_sur[0:20].argmax()
else:
skew_h = - angle_sur[160:180].argmax()
return skew_h,skew_v
1.3.2、旋转
首先计算出目标图像上四个顶点的坐标,再使用OpenCV的getPerspectiveTransform()计算透视变换矩阵,最后使用OpenCV的warpPerspective()进行透视变换
## v:垂直方向旋转
def v_rot(img,angel,shape,max_angel):
## shape[0]高 shape[1]宽
size_o = [shape[1],shape[0]]
## size = (宽 + 高*cos(最大角),高)
size = (shape[1] + int(shape[0]*np.cos((float(max_angel )/180) * 3.14)),shape[0])
## interval = |sin(倾角)*高|
interval = abs( int( np.sin((float(angel) /180) * 3.14)* shape[0]));
## 原图像的坐标
pts1 = np.float32([[0,0] ,[0,size_o[1]],[size_o[0],0],[size_o[0],size_o[1]]])
if(angel>0):
pts2 = np.float32([[interval,0],[0,size[1] ],[size[0],0 ],[size[0]-interval,size_o[1]]])
else:
pts2 = np.float32([[0,0],[interval,size[1] ],[size[0]-interval,0 ],[size[0],size_o[1]]])
## getPerspectiveTransform 用于计算透视变换矩阵
## getPerspectiveTransform( // 返回3x3透视变换矩阵
## const cv::Point2f* src, // 源图像四个顶点坐标(点数组)
## const cv::Point2f* dst // 目标图像上四个顶点的坐标(点数组)
## )
M = cv2.getPerspectiveTransform(pts1,pts2);
## 透视变换
dst = cv2.warpPerspective(img,M,size);
return dst,M
1.4、车牌精定位
def fitLine_ransac(pts,zero_add = 0 ):
if len(pts)>=2:
[vx, vy, x, y] = cv2.fitLine(pts, cv2.DIST_HUBER, 0, 0.01, 0.01)
lefty = int((-x * vy / vx) + y)
righty = int(((136- x) * vy / vx) + y)
return lefty+30+zero_add,righty+30+zero_add
return 0,0
## 精定位算法
def findContoursAndDrawBoundingBox(image_rgb):
line_upper = [];
line_lower = [];
line_experiment = []
grouped_rects = []
gray_image = cv2.cvtColor(image_rgb,cv2.COLOR_BGR2GRAY)
## 15级自适应二值化
for k in np.linspace(-50, 0, 16):
binary_niblack = cv2.adaptiveThreshold(gray_image,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,17,k)
## 找出轮廓
contours, hierarchy = cv2.findContours(binary_niblack.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
## boundingRect()返回外部矩形边界
bdbox = cv2.boundingRect(contour)
if ((bdbox[3]/float(bdbox[2])>0.7 and bdbox[3]*bdbox[2]>100 and bdbox[3]*bdbox[2]<1200) or (bdbox[3]/float(bdbox[2])>3 and bdbox[3]*bdbox[2]<100)) :
line_upper.append([bdbox[0],bdbox[1]])
line_lower.append([bdbox[0]+bdbox[2],bdbox[1]+bdbox[3]])
line_experiment.append([bdbox[0],bdbox[1]])
line_experiment.append([bdbox[0]+bdbox[2],bdbox[1]+bdbox[3]])
rgb = cv2.copyMakeBorder(image_rgb,30,30,0,0,cv2.BORDER_REPLICATE)
leftyA, rightyA = fitLine_ransac(np.array(line_lower),3)
rows,cols = rgb.shape[:2]
leftyB, rightyB = fitLine_ransac(np.array(line_upper),-3)
rows,cols = rgb.shape[:2]
pts_map1 = np.float32([[cols - 1, rightyA], [0, leftyA],[cols - 1, rightyB], [0, leftyB]])
pts_map2 = np.float32([[136,36],[0,36],[136,0],[0,0]])
mat = cv2.getPerspectiveTransform(pts_map1,pts_map2)
image = cv2.warpPerspective(rgb,mat,(136,36),flags=cv2.INTER_CUBIC)
image,M = fastDeskew(image)
return image
2、CNN训练
2.1、获取batch_size张图片用于训练
train_data_dir = r'F:\train' # 根据实际情况替换
test_data_dir = r'F:\test'
train_file_name_list = os.listdir(train_data_dir)
## 把彩色图像转为灰度图像(色彩对识别验证码没有什么用)
def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
return gray
else:
return img
def gen_train_data(batch_size=32):
'''
生成训练数据
'''
train_image_list = random.sample(train_file_name_list, batch_size)
x_data = []
y_data = []
for train_image in train_image_list:
if train_image.endswith('.gif'):
image = Image.open(os.path.join(train_data_dir, train_image))
image_np = np.array(image)
image_np = convert2gray(image_np)
assert image_np.shape == (60, 160)
image_np = np.expand_dims(image_np, 2)
x_data.append(image_np)
y_data.append(np.array(list(train_image.split('.')[0])).astype(np.int32))
x_data = np.array(x_data).astype(np.float) ## x_data.shape = (64, 60, 160, 1)
y_data = np.array(y_data) ## y_data.shape = (64, 7)
return x_data, y_data
2.2、构建CNN网络
X = tf.placeholder(tf.float32, name="input") ## 亦即 X = x_data , so X.shape = (batch_size, 60, 160, 1)
Y = tf.placeholder(tf.int32) ## 亦即 Y = y_data , so Y.shape = (batch_size, 7)
keep_prob = tf.placeholder(tf.float32)
y_one_hot = tf.one_hot(Y, 65, 1, 0) ## y_one_hot.shape = (batch_size , 7 , 10)
y_one_hot = tf.cast(y_one_hot, tf.float32) ## tf.cast()类型转换
# keep_prob = 1.0
def net(w_alpha=0.01, b_alpha=0.1):
'''
网络部分,三层卷积层,一个全连接层
:param w_alpha:
:param b_alpha:
:return: 网络输出,Tensor格式
'''
conv2d_size = 3 ## 卷积核大小
featuremap_num1 = 32 ## 卷积层1输出的featuremap的数量
featuremap_num2 = 64 ## 卷积层2输出的featuremap的数量
featuremap_num3 = 64 ## 卷积层3输出的featuremap的数量
strides_conv2d1 = [1, 1, 1, 1] ##卷积层1的卷积步长
strides_conv2d2 = [1, 1, 1, 1] ##卷积层2的卷积步长
strides_conv2d3 = [1, 1, 1, 1] ##卷积层3的卷积步长
strides_pool1 = [1, 2, 2, 1] ## 卷积层1的池化步长
strides_pool2 = [1, 2, 2, 1] ## 卷积层2的池化步长
strides_pool3 = [1, 2, 2, 1] ## 卷积层3的池化步长
ksize_pool1 = [1, 2, 2, 1] ## 卷积层1的池化size
ksize_pool2 = [1, 2, 2, 1] ## 卷积层2的池化size
ksize_pool3 = [1, 2, 2, 1] ## 卷积层3的池化size
neuron_num = 1024 ## 神经元数量
FC_dim1 = float(img_height)/(strides_pool1[1]*strides_pool2[1]*strides_pool3[1])
FC_dim2 = float(img_width) /(strides_pool1[2]*strides_pool2[2]*strides_pool3[2])
FC_dim = int(round(FC_dim1) * round(FC_dim2) * featuremap_num3)
## -1代表先不考虑输入的图片有多少张,1是channel的数量
x_reshape = tf.reshape(X,shape = [-1, img_height, img_width, 1])
## 构建卷积层1
## tf.Variable()定义变量
## tf.random_normal()生成N维服从正太分布的数据
w_c1 = tf.Variable(w_alpha * tf.random_normal([conv2d_size, conv2d_size, 1, featuremap_num1])) # 卷积核3*3,1个channel,16个卷积核,形成16个featuremap
b_c1 = tf.Variable(b_alpha * tf.random_normal([featuremap_num1])) # 16个featuremap的偏置
## tf.nn.relu()激活函数,激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
## tf.nn.bias_add(value, bias, data_format=None, name=None),将偏差项bias加到values上
## tf.nn.conv2d()卷积计算的核心函数,讲解请参考https://www.cnblogs.com/qggg/p/6832342.html
## padding参数中SAME代表给边界加上Padding让卷积的输出和输入保持相同的尺寸
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x_reshape, w_c1, strides=strides_conv2d1, padding='SAME'), b_c1))
## tf.nn.max_pool()最大值池化
## 经过tf.nn.max_pool(strides=[1, 2, 2, 1])后,feature_map在各个维度上都变为一半
conv1 = tf.nn.max_pool(conv1, ksize=ksize_pool1, strides=strides_pool1, padding='SAME')
## tf.nn.dropout()此函数是为了防止在训练中过拟合的操作,将训练输出按一定规则进行变换
conv1 = tf.nn.dropout(conv1, keep_prob)
## 构建卷积层2
w_c2 = tf.Variable(w_alpha * tf.random_normal([conv2d_size, conv2d_size, featuremap_num1, featuremap_num2])) # 注意这里channel值是16
b_c2 = tf.Variable(b_alpha * tf.random_normal([featuremap_num2]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=strides_conv2d1, padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=ksize_pool2, strides=strides_pool2, padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
## 构建卷积层3
w_c3 = tf.Variable(w_alpha * tf.random_normal([conv2d_size, conv2d_size, featuremap_num2, featuremap_num3]))
b_c3 = tf.Variable(b_alpha * tf.random_normal([featuremap_num3]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=strides_conv2d1, padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=ksize_pool3, strides=strides_pool3, padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
## 构建全连接层,这个全连接层的输出才是最后要提取的特征
# Fully connected layer
# 随机生成权重
## https://stackoverflow.com/questions/43010339/python-tensorflow-input-to-reshape-is-a-tensor-with-92416-values-but-the-re
# w_d = tf.Variable(w_alpha * tf.random_normal([3 * 8 * 64, 128]))
# w_d = tf.Variable(w_alpha * tf.random_normal([163840, 128])) # 128个神经元
w_d = tf.Variable(w_alpha * tf.random_normal([FC_dim, neuron_num])) # 1024个神经元
# 随机生成偏置
b_d = tf.Variable(b_alpha * tf.random_normal([neuron_num]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
## 最后要提取的特征
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
## 输出层
w_out = tf.Variable(w_alpha * tf.random_normal([neuron_num, 65])) # 40个神经元
b_out = tf.Variable(b_alpha * tf.random_normal([65]))
out = tf.add(tf.matmul(dense, w_out), b_out) ## out.shape = (64,65)
return out
2.3、执行训练
def train():
batch_size_train = 64 ## 一个训练batch的数量
batch_size_test = 100 ## 一个测试batch的数量
cnn = net()
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=cnn, labels=y_one_hot))
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=cnn, labels=y_one_hot))
# optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰减
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
print('开始执行训练')
predict = net()
max_idx_p = tf.argmax(predict, 2) ## 通过argmax返回的index可得出识别的图片的字符值
max_idx_l = tf.argmax(tf.reshape(y_one_hot, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
step = 0
tf.global_variables_initializer().run()
while True:
x_data, y_data = gen_one_batch(batch_size_train)
loss_, cnn_, y_one_hot_, optimizer_ = sess.run([loss, cnn, y_one_hot, optimizer],
feed_dict={Y: y_data, X: x_data, keep_prob: 0.75})
print('step: %4d, loss: %.4f' % (step, loss_))
## 每运行1w步,保存一次
if 0 == (step % 10000):
saver.save(sess, "tmp10000/", global_step=step)
# 每100 step计算一次准确率
if 0 == (step % 100):
x_data, y_data = gen_one_batch(batch_size_test)
acc = sess.run(accuracy, feed_dict={X: x_data, Y: y_data, keep_prob: 1.0})
print('准确率计算:step: %4d, accuracy: %.4f' % (step, acc))
if acc > 0.98:
saver.save(sess, "tmp/", global_step=step)
print("训练完成,模型保存成功!")
break
step += 1
3、车牌识别
3.1、读取1.4中精定位获取的图片
def gen_test_data():
x_data = []
y_data = []
for parent, dirnames, filenames in os.walk(test_data_dir, followlinks=True):
for filename in filenames:
gif_file_path = os.path.join(parent, filename)
if gif_file_path.endswith('.gif'):
captcha_image = Image.open(gif_file_path)
captcha_image_np = np.array(captcha_image)
assert captcha_image_np.shape == (60, 160)
captcha_image_np = np.expand_dims(captcha_image_np, 2).astype(np.float32)
x_data.append(captcha_image_np)
y_data.append(filename.split('.')[0])
return x_data, y_data
3.2、使用CNN训练模型对精定位图片进行识别
def test():
if not os.path.exists(test_data_dir):
raise RuntimeError('测试数据目录不存在,请检查"%s"参数' % 'test_data_dir')
if tf.train.latest_checkpoint('tmp/') is None:
raise RuntimeError('未找到模型文件,请先执行训练!')
print('%s' % '开始执行测试')
x, y = gen_test_data()
print('测试目录文件数量:%d' % len(x))
saver = tf.train.Saver()
sum = 0
correct = 0
error = 0
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('tmp/'))
for i, image in enumerate(x):
answer = y[i]
image = image.reshape((1, img_height , img_width, 1))
cnn_out = sess.run(cnn, feed_dict={X: image, keep_prob: 1})
# print(cnn_out)
cnn_out = cnn_out[0]
predict_vector = np.argmax(cnn_out, 1)
predict = ''
for c in predict_vector:
predict += str(c)
print('预测:%s,答案:%s,判定:%s' % (predict, answer, "√" if predict == answer else "×"))
sum += 1
if predict == answer:
correct += 1
else:
error += 1
print("总数:%d,正确:%d,错误:%d" % (sum, correct, error))
if __name__=='__main__':
# 测试
test()
4、Mysql存储
将识别到的车牌保存到Mysql中
import pymysql
import datetime
import Ipynb_importer
from car_recognise import Record2Mysql
from time import sleep
db = pymysql.connect(host='localhost',port=3306,user='root',password='root',database='car_record',charset='utf8')
cursor = db.cursor()
time_in = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
sleep(2)
time_out = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
path_org,path_cut,predict_result = Record2Mysql()
sql = """INSERT INTO car_info(img_org,img_cut, predict, times, time_in,time_out)VALUES ('"""+ \
path_org + "','" + path_cut + "','" + predict_result + "','" + "21'" + ",'" + time_in + "','" + time_out + "')"
cursor.execute(sql)
db.commit()
db.close()
5、总结
此识别过程中,最棘手的问题就是倾斜矫正。由于不知道透视变换的使用方法,一旦遇到倾斜的车牌,基本不能正确识别。经过透视变换后,可有效切除铆钉的影响,从而正确识别到车牌字符。识别率可达95.8%
例如这张车牌,其识别结果总是粤RH469Z


无需安装部署,在线快速体验 Byzer
更多推荐
 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)