
sql中的left join 查询
join 是 SQL查询中很常见的一种操作,具体来讲有join,left join, right join,full join等很多形式。具体的原理如下图所示。但其中最常见的还是使用left join 。本文代码在mysql和hive中均测试通过,代码本身难度和长度都不大,我准备了测试数据的mysql和hive代码,如果觉得有必要,你可以在后台回复“left”获取,方便自己修改和练习。...
join 是 SQL查询中很常见的一种操作,具体来讲有join,left join, right join,full join等很多形式。具体的原理如下图所示。但其中最常见的还是使用left join 。
本文代码在mysql和hive中均测试通过,代码本身难度和长度都不大,我准备了测试数据的mysql和hive代码,如果觉得有必要,你可以在后台回复“left”获取,方便自己修改和练习。

left join 通俗的解释:以左表为主表,返回左表的所有行,如果右表中没有匹配,则依然会有左表的记录,右表字段用null填充。看起来非常好理解,但实际操作的过程中可能会有一些很容易被忽略的点。
一、left join 之后的记录有几条
关于这一点,是要理解left join执行的条件。在A join B的时候,我们在on语句里指定两表关联的键。只要是符合键值相等的,都会出现在结果中。这里面有一对一,一对多,多对多等几种情况。我们用例子来说明。
1、一对一
这种情况最好理解。t_name表,有id,name(用户名称),sex(性别),dt(注册日期)等字段。t_age表。有id,age(年龄),province(省份),dt(更新日期)等字段。表中包含的信息如下:
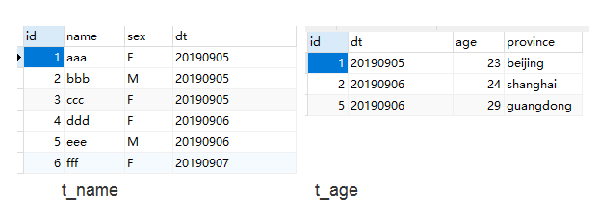
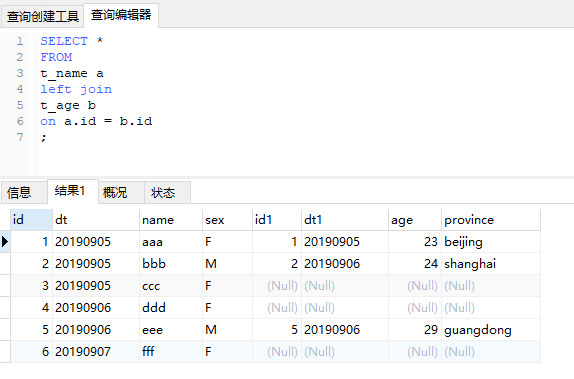
现在我们进行t_name(左表,别名a)和t_age(右表,别名b)的left join 操作,关联键为id。a表有6条记录,b表有3条记录,且关键的键是唯一的,因此最终结果以a表为准有6条记录,b表有3条关联不上,相应的记录中,b表所有的字段都为空。
2、一对多
这回我们用t_age作为左表,关联条件为dt。重点看dt为20190905的记录。由于右表有3条20190905,这三条在关联的时候都满足关联条件,因此最终的结果会有3条记录是20190905。
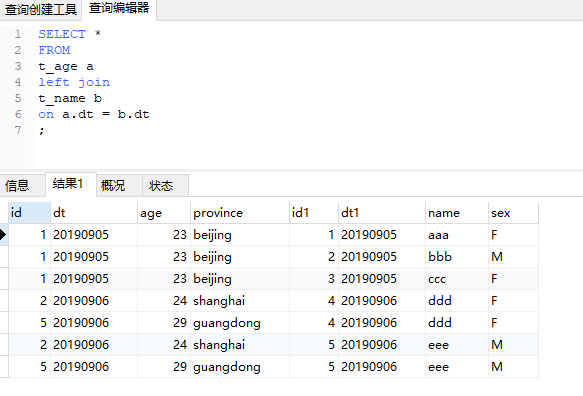
这回为准的表是t_age表,但显然结果并不是原本的3条记录,而是7条:20190905 3条,20190906 4条。如果你不太理解,可以继续往下看。
3、多对多
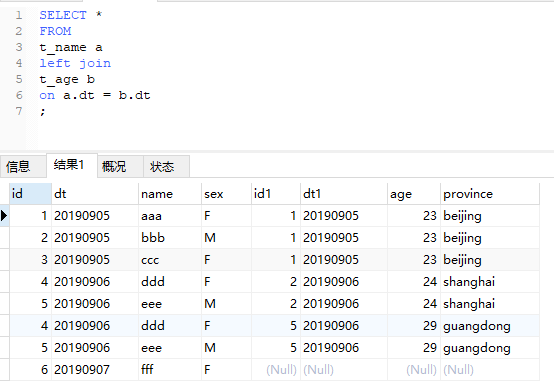
上面例子中,20190906的记录最终有4条,同样是因为满足了关联条件,是一种2对2的情况。这里我们还是回到t_name表做主表的情况,用dt来关联。可以预见,与2中相比,这次结果中会多一行20190907的,而b表相应的字段依然为空。
2和3中我们看到了一对多和多对多的情况,其实前者是后者的特例。我们只是很简要的把两个表关联之后所有的字段都列出来了,但实际中可能需要做一些统计,聚合等。这里提醒大家在写关联条件之前,最好思考一下最终的结果是什么样的,最终可能有几行,会不会在计数的时候多统计,哪些行可能会存在空值,哪些字段可能会存在空值等。不要因为想当然而犯了错误。这里算是抛砖引玉,感兴趣的同学可以看看这篇博客,进一步学习,
https://www.cnblogs.com/qdhxhz/p/10897315.html
二、left join 的执行原理
接下来我们进一步看一下连接条件写在on里和写在where里的区别。在这之前,我们可以看看left join的具体执行逻辑。我参考了网上以为大神的博客:
https://developer.aliyun.com/article/718897,总结如下
mysql采用嵌套循环的方式处理left join。
SELECT * FROM LT LEFT JOIN RT ON P1(LT,RT)) WHERE P2(LT,RT)
其中P1是on过滤条件,缺失则认为是TRUE,P2是where过滤条件,缺失也认为是TRUE,该语句的执行逻辑可以描述为:
- FOR each row lt in LT {// 遍历左表的每一行
- BOOL b = FALSE;
- FOR each row rt in RT such that P1(lt, rt) {// 遍历右表每一行,找到满足join条件的行
- IF P2(lt, rt) {//满足 where 过滤条件
- t:=lt||rt;//合并行,输出该行
- }
- b=TRUE;// lt在RT中有对应的行
- }
- IF (!b) { // 遍历完RT,发现lt在RT中没有有对应的行,则尝试用null补一行
- IF P2(lt,NULL) {// 补上null后满足 where 过滤条件
- t:=lt||NULL; // 输出lt和null补上的行
- }
- }
- }
如果代码看不懂,直接看结论就好:
- 如果想对右表进行限制,则一定要在on条件中进行,若在where中进行则可能导致数据缺失,导致左表在右表中无匹配行的行在最终结果中不出现,违背了我们对left join的理解。因为对左表无右表匹配行的行而言,遍历右表后b=FALSE,所以会尝试用NULL补齐右表,但是此时我们的P2对右表行进行了限制,NULL若不满足P2(NULL一般都不会满足限制条件,除非IS NULL这种),则不会加入最终的结果中,导致结果缺失。
2. 如果没有where条件,无论on条件对左表进行怎样的限制,左表的每一行都至少会有一行的合成结果,对左表行而言,若右表若没有对应的行,则右表遍历结束后b=FALSE,会用一行NULL来生成数据,而这个数据是多余的。所以对左表进行过滤必须用where。
我们再来看看实例,返回来研究这段话可能更好理解一些。
1、只有1个on条件
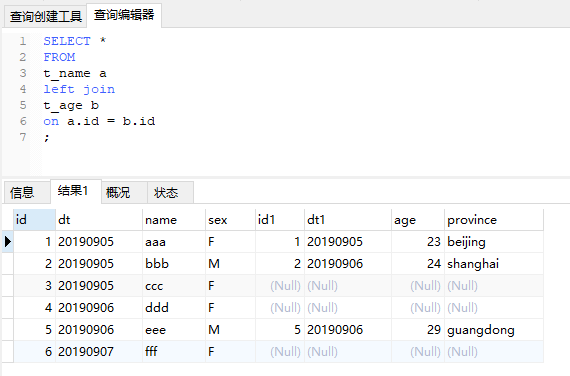
这里可以直接看第一部分中的例子。最终会输出以左表为准,右表匹配不上补null的结果,但可能会有多对多的情况。
2、有2个on条件
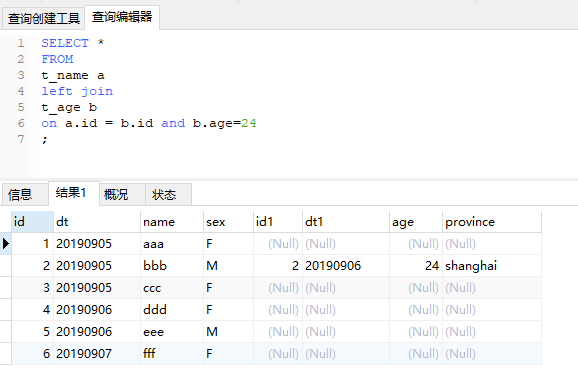
上图是在关联条件中增加了b.age=24之后的输出结果。由于对b表进行了限制,满足条件的只有一个,但是由于没有where条件,因此依然要以左表为准,又因为是一对一,所以输出还是左表的记录数。更极端的,我们可以“清空”b表。
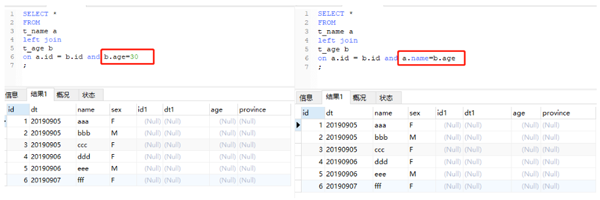
以上两种情况,在b表中都没有符合条件的结果,因此在以左表为准的基础上,右边的所有字段都为空。
3、有where的情况
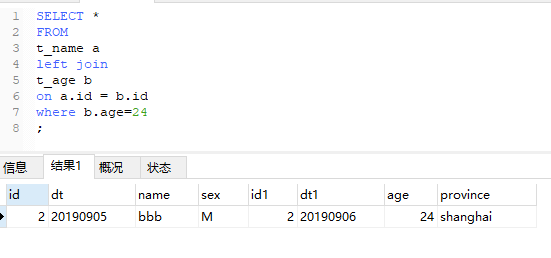
将b.age=24写到where里,发现结果中只有这一行,打破了“left join”以左表为主的限制。同样再来看下后两种情况写到where里会发生什么:
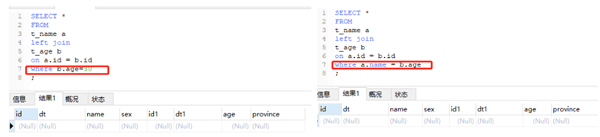
没错,结果全部是为空的。因为where 在 on 后面执行,而on生成的结果里没有满足条件的记录!
这里给出两个结论:
1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
4、有is null 或者有 is not null的情况
当条件写在on中:
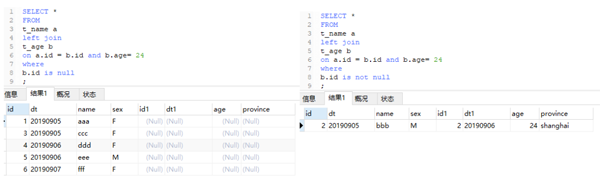
当条件写在where 中:
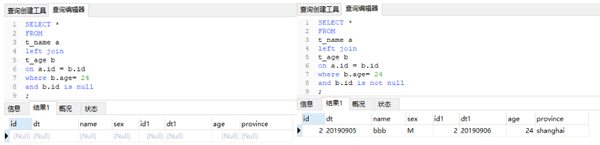
直观的我们理解,WHERE … IS NULL 子句将从匹配阶段后的数据中过滤掉不满足匹配条件的数据行。对于条件写在on中的情况,又可以说,is null是否定匹配条件,is not null是肯定匹配条件。对于条件写在where中的,其实相比之下更容易理解,要看已有的where条件产生的结果是什么。读者可以从上面的例子中思考一下。
三、看两个实际案例
经过上面的讨论,我们来看两个案例,进一步理解和思考一下left join 的用法。
1、案例1
这个案例来自于一篇网络博客,前文有提到。链接:
https://developer.aliyun.com/article/718897
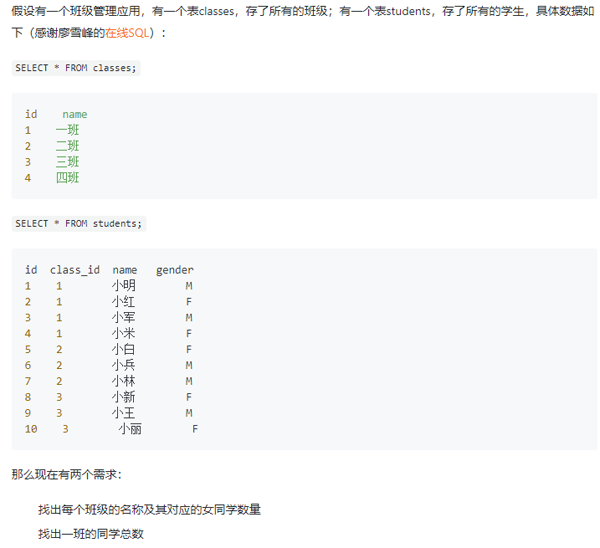
大家可以先思考一下怎么写再到原文看答案。事实上,每个需求都很容易有两种写法,区别就在于条件是写在where中还是写在on中。判断的原则就是我们需要保证结果中数据不缺失也不多余。需求1的条件需要写在on中(保证结果不缺失),需求2的条件需要写在where中(保证结果不多余)。
2、案例2
假设现在有一个用户活跃表t_active,记录了每天活跃的uid和相应的活跃日期。现在想要看距离某一天日期差为0天,1天,2天,3天…活跃的用户在当天还有多少活跃(也就是一个留存的概念)。期望得到的如下表所示:
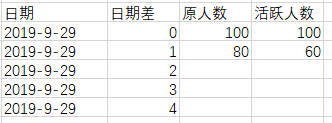
对于表中数据,我们可以这样理解。距离2019-09-29 0天(也就是2019-09-29)的活跃人数为100,2019-09-29当天活跃的还剩100,距离2019-09-29 1天(也就是2019-09-28)的活跃人数为80,2019-09-29当天还剩60。以此类推。
对于这个需求,我们可以使用left join进行自关联,用之前活跃的天作为左表,最终期望计算的天作为右表,计算日期差,并进行左右表分别计数。初步的SQL如下:(数据是自己编的)
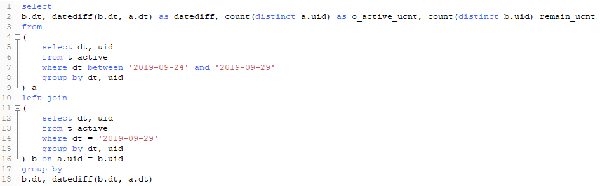
在往下看之前请确认你理解了需求目标,并先思考下,以上的写法有问题吗?能否得到上面期望的结果?
原始数据和这段SQL运行的结果如下:
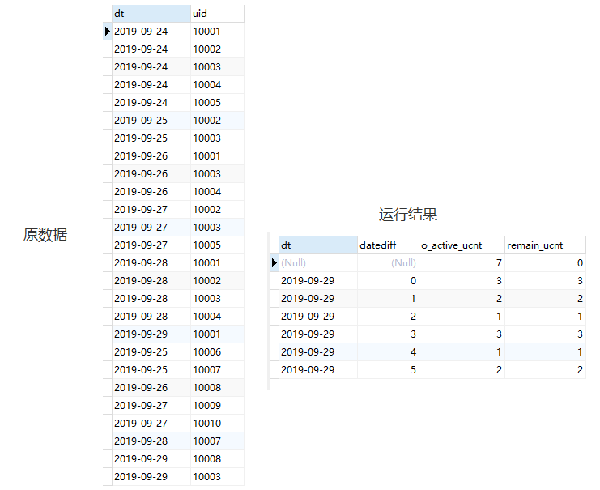
运行结果中出现了dt和datediff为null的情况,你能想象的到这是为什么吗?而且当dt不为null的时候,最后两列的数据是相同的,显然和我们的预期不符。这是什么原因呢?我们来逐步看一下。
首先,我们使用left join 的方式应该是没有问题的,我们先看看不加任何计算的,select * 的结果是啥。
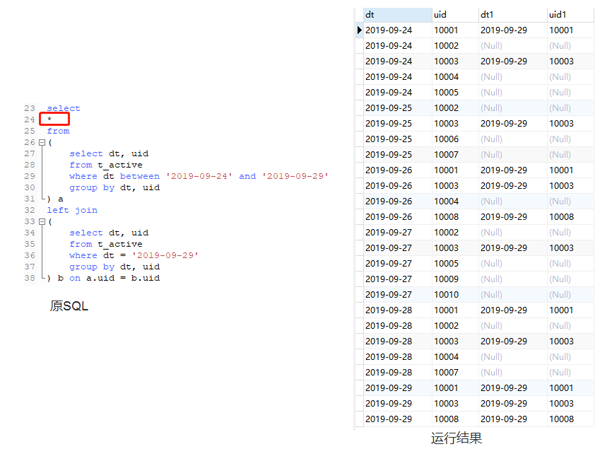
可以看到,这相当于是前文提到的不加where 条件的一对一关联,结果会以左表为准,关联不上的用null补齐。值得注意的是,关联不上的日期是null值,而null值在参与datediff的计算时,结果会是null。到这里你是不是明白一点了。由于null值参与计算,导致最终datediff 有null值,并且计数的时候,由于null值存在,最终用日期差作为维度的时候,导致左表和右表的数量是一样的。如下面代码所示:
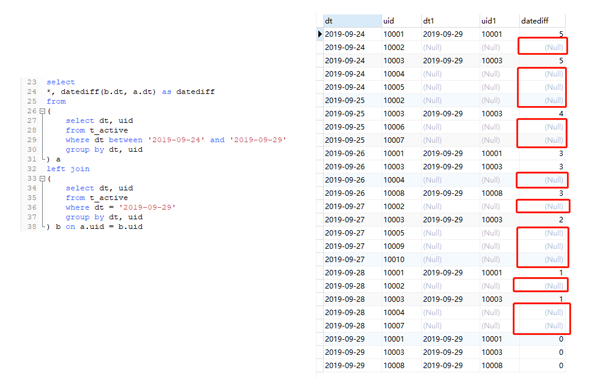
从上面的结果我们可以推演出最开始的SQL运行结果。例如,datediff=5的时候,共两条记录,左表右表的count(distinct uid)都为2。datediff为null的时候,左表结果为7,右表为0,其他的以此类推,和前面的结果是一样的。这样我们就知道了,没有达到预期的根源在于存在空的日期。那么怎么解决这个问题呢,显然就是把空日期填补上就可以了。可以使用case when 当右表日期关联不上的时候,用相应日期补足。代码如下:
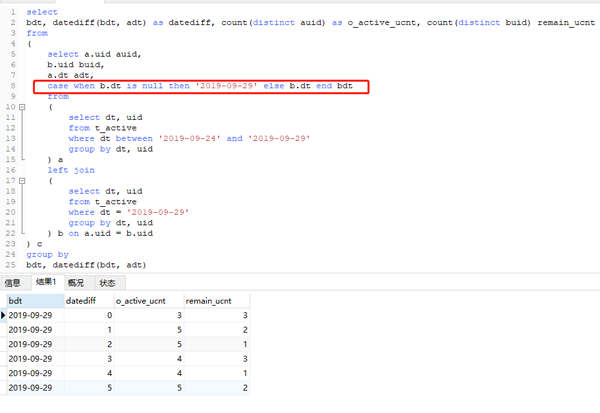
可以看到最终得到了想要的结果,以最后一行为例,它表示,距离2019-09-29 5天的那天(也就是2019-09-24)活跃的人数有5个,那些人在2019-09-29仍然活跃的有2人,你可以看一下明细数据核对一下。其余的以此类推。我们使用case when 把日期写死了,这个是建立在我们知道是哪天的基础上的。实际中可能是一个变量,但一定也是一个固定的值,需要具体情况具体分析。
四、总结
本文我们学习了left join的原理和实践中可能会遇到的问题。包括关联时结果中的记录数,关联条件写在on和where中的区别,where语句中存在is null的时候如何理解,最后用实例帮助大家进行理解。在此过程中参考了网上的一些博客,大家可以在阅读本文的基础上进行查阅。希望对你有所帮助!后台回复“left”,可以获取本文测试所用的数据集合代码;

无需安装部署,在线快速体验 Byzer
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)