
python爬虫之xpath格式转换与去除多余标签、解决部分重定向问题的方法
写在前面的话: 实习了半个多月,总结一下学到的内容,还有在做项目中遇到的问题及其解决方式。一. xpath的一些用法1. 转换格式将解析过的 xpath 转换成 HTML 字符串为什么会用到这个,是因为之前在爬取一些js包含的内容时用到了js2xml二. 数据库的连接1. 连接为了项目的维护,所以形成了加入大量异常捕捉以及打日志的习惯,便于排错。import pymysqlpymysql.inst
写在前面的话: 实习了半个多月,总结一下学到的内容,还有在做项目中遇到的问题及其解决方式。由于找的爬虫实习岗,所以大多都是数据采集,数据库,xpath等的使用,都是为了学习巩固,有什么不对的地方还希望各位大佬指正出来,不胜感激。
- 附上一个特别好用的链接,能直接获取页面,类似
postman。 Convert curl syntax to Python 使用方法也在页面下面
一、xpath的一些用法
1. 转换格式
- 将解析过的
xpath转换成HTML字符串 - 为什么会用到这个,是因为之前在爬取一些js包含的内容时用到了
js2xml,具体可参考连接 爬虫之 JS(返回非 json 数据)的爬取 ,得到的结果是xpath格式,但是又不知道内容是什么
……
html = etree.HTML(text)
content = etree.tostring(html, encoding="utf-8").decode("utf-8")
2. 去除不想要的标签
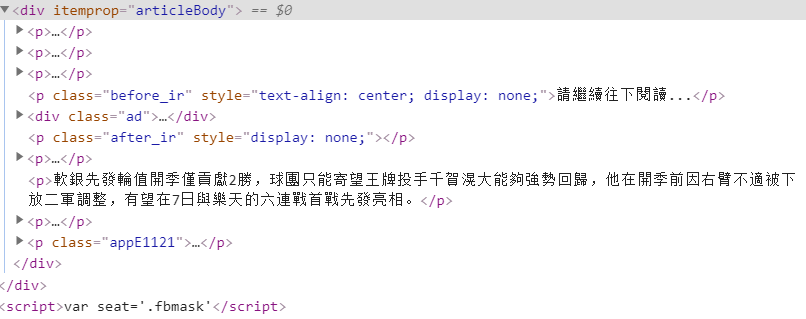
- 我要获取div里面的内容,但是用xpath获取的时候后面那个script也会被包含在内,输出text后含有很多js的函数(跟网页源代码有关),所以要去除这一部分函数
- 详情参考 链接
for bad in html.xpath('//div[@itemprop="articleBody"]//script'):
bad.getparent().remove(bad)
content = html.xpath('//div[@itemprop="articleBody"]//text()')
content = ' '.join([i.strip() for i in content])[1:]
3. 顺便附上 BeautifulSoup 去除不想要的标签
二、解决部分重定向以及检查元素与源码不匹配的问题
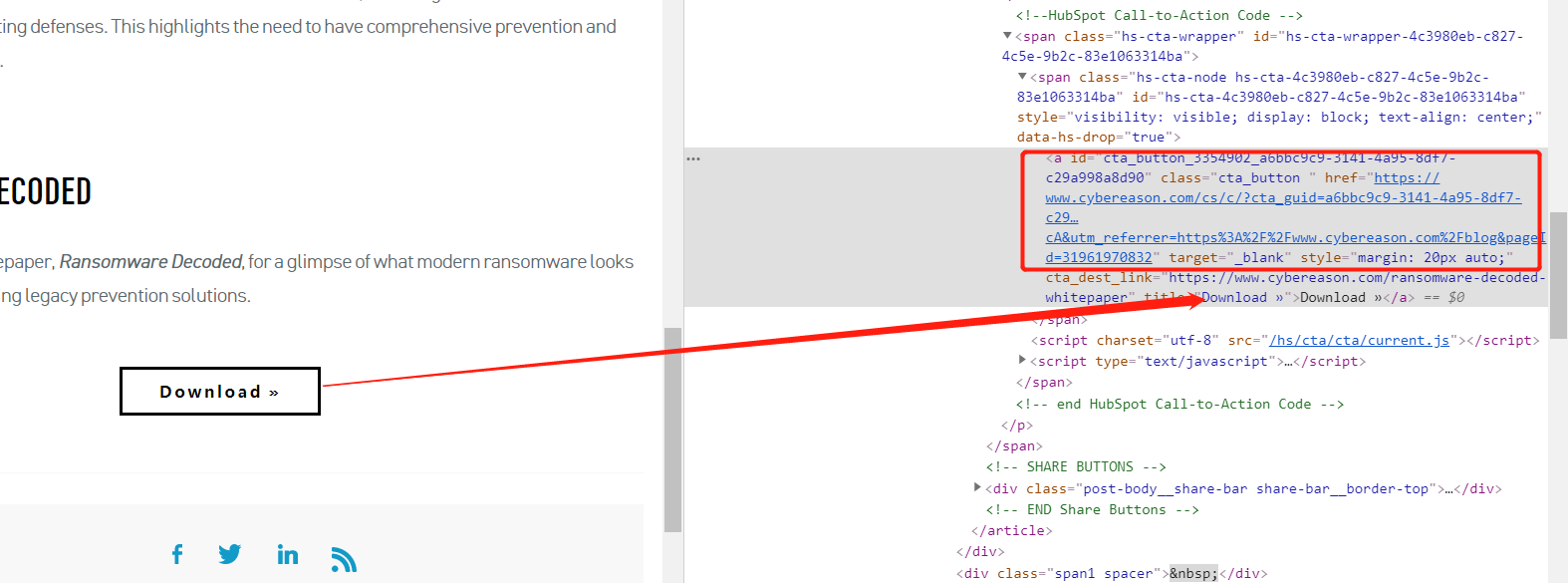
-
如上图,我要下载点击
download后的pdf,点击之后会发现两个问题- 审查元素看到的链接并不在源码内,具体看下图(通过搜索
download字段查到),可以看到两者链接不一样

- 点击后需要提交信息才能获取到
pdf

- 审查元素看到的链接并不在源码内,具体看下图(通过搜索
1. 解决链接获取问题
由于是整个网站(基于该域名下的所有子网站)需要获取,所以采用正则的方式解决,一些具体的需求加判断就行了。该网站点开后 需要提交信息,但是不需要注册 ,那么一般就会有个 重定向链接 或在 js 代码里,在 源码 中找到就行了,可看下图,因此所有的目的就只有一个——找到最终含有 pdf 的重定向链接。
sub_text = re.findall('<a href="(https://cta-redirect.*?)" target="_blank">', sub_html, re.S|re.M)
# 获取结果
# ['https://cta-redirect.hubspot.com/cta/redirect/3354902/4c3980eb-c827-4c5e-9b2c-83e1063314ba]
response = requests.get(sub_text[0], headers=headers, allow_redirects=True).text
2. 解决重定向问题
点开该链接,你会发现这个链接还是重定向到某个链接,接下来进行 requests 请求,仍然获取不到,加上重定向参数 allow_redirects=True 仍然不会直接指向所需链接。得到如下结果
<!-- 上述结果如下 -->
<!DOCTYPE HTML>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta http-equiv="refresh" content="0;url=https://www.cybereason.com/ransomware-decoded-whitepaper">
<script>
var referrer = encodeURIComponent(document.referrer);
var redirectUrl = "https://www.cybereason.com/ransomware-decoded-whitepaper";
if(referrer != "" && referrer !== null) {
if(redirectUrl.indexOf("&") != -1) {
redirectUrl = redirectUrl + "&" + "utm_referrer=" + referrer;
} else {
redirectUrl = redirectUrl + "?" + "utm_referrer=" + referrer;
}
}
window.location.href = redirectUrl
</script>
<title>Redirecting...</title>
</head>
<body>
<a href="https://www.cybereason.com/ransomware-decoded-whitepaper">Click here if you're not redirected automatically...</a>
</body>
</html>
不过在这里获得的内容可以看到重定向的链接,那么再进行一次重定向即可
redirect_url = re.findall('redirectUrl = "(http.*?)";?', response, re.S|re.M)[0]
print(redirect_url)
# https://www.cybereason.com/ransomware-decoded-whitepaper
""""""
3. 解决提交信息才能获取内容的问题
上述链接打开直接查看源码搜索 pdf 即可看到需要的信息,会发现在 script 标签里,用 正则 获取就可以了

text = requests.get(redirect_url, headers=headers).text
pdf_text = re.findall('redirectUrl: "(https:.*?.pdf)', text, re.S|re.M)[0].replace('\\', '')
print(pdf_text)
# https://www.cybereason.com/hubfs/2020_05_Ransomware_Decoded.pdf
正则的使用也是马马虎虎,会一些基本的匹配,太复杂的写不来,也得多练习~
三、关于时间的一些处理
1. 时间正规化
- 关键就是两个函数:strptime(str, str对应的格式), strftime(你想要的格式)
- 前者将其解析为datetime形式,后者转换为你需要的形式
strptime(str, str对应的格式) 对应的格式意思就是 月份有对应的字母,年份也一样,哪里用符号隔开,就加上相同的符号,对比下面的两个代码就理解了。
具体对应字母可参考 python对时间日期做格式化
time = 'Apr 09, 2020'
time = datetime.datetime.strptime(time.strip(), '%b %d, %Y').strftime('%Y-%m-%d %H:%M:%S')
time = 'June/09/2020'
time = datetime.datetime.strptime(time.strip(), '%B/%d/%Y').strftime('%Y-%m-%d %H:%M:%S')
2. 当前时间加减某一时间
if '分鐘' in time:
num = int(re.findall('\d+', time)[0])
time = (datetime.datetime.now() + datetime.timedelta(minutes=-num)).strftime("%Y-%m-%d %H:%M:%S")
elif '小時' in time:
num = int(re.findall('\d+', time)[0])
time = (datetime.datetime.now() + datetime.timedelta(hours=-num)).strftime("%Y-%m-%d %H:%M:%S")
四、 数据库的连接
具体的创建表什么的还得学一下,都是指令的事,就是怎么跟 py 能够接在一起
1. 连接
为了项目的维护,所以形成了加入大量异常捕捉以及打日志的习惯,便于排错。
import pymysql
pymysql.install_as_MySQLdb()
from Log import Log
log = Log(__name__).getlog()
def getConnection():
return pymysql.connect(Config.db_url, Config.db_user, db_password, Config.db_database, charset='utf8',
connect_timeout=Config.timeout,read_timeout=Config.timeout_page, write_timeout=Config.timeout_page)
def closeConnection(connection):
# 关闭数据库连接
connection.close()
2. 存入数据、取出数据
def update(sql, data):
"""
:param sqlupdate: 直接定义需呀执行的sql , 支持 delete, update, insert
:param data: 直接定义对应 delete, update, insert 中的 db.table.cols 信息
:return:
"""
try:
dbc = getConnection()
except pymysql.err as e:
log.error('[UPDATEDB] ' + str(e))
cursor = dbc.cursor()
try:
cursor.execute(sql, data)
dbc.commit()
except pymysql.err as e:
log.error('[UPDATEDB] ' + str(e))
finally:
cursor.close()
dbc.close()
# 如果没有可传的参数就传 ()
def select(sql, data):
try:
dbc = getConnection()
except pymysql.err as e:
log.error('[SELECT] ' + str(e))
cursor = dbc.cursor()
try:
cursor.execute(sql, data)
results = cursor.fetchall();
except pymysql.err as e:
log.error('[SELECT] ' + str(e))
finally:
cursor.close()
dbc.close()
return results

无需安装部署,在线快速体验 Byzer
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)