
千万级数据表如何索引快速查找
Mysql索引数据结构Mysql索引数据结构索引1.二叉树的优缺点优点缺点2.红黑树的优缺点优点缺点如何去优化?3.B-Tree4.B+TreeB+Tree特点底层为什么查找这么快的原因1.慢Sql查询:执行时间几秒, 几十秒,怎么去优化????2.索引,本来需要执行几秒几十秒的查询,加上合适的索引可能几十毫秒就结束了3.为什么?4.底层怎么实现的?索引索引是帮助MySQL高效获取数据的排好序的数
Mysql索引数据结构
1.慢Sql查询:执行时间几秒, 几十秒,怎么去优化????
2.索引,本来需要执行几秒几十秒的查询,加上合适的索引可能几十毫秒就结束了
3.为什么?
4.底层怎么实现的?
索引
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构:
二叉树
红黑树
Hash表
B-Tree
MySQL底层为什么会选择像B-Tree,B+Tree这样的数据结构来存储我们的索引?
MySQL早期版本选择二叉树,红黑树来存储我们的索引,只不过这些数据结构还存在一些小问题。
1.二叉树的优缺点
优点
COL2作为我们的索引,原来需要做6次I/O,现在只需要做3次I/O,性能提升了一倍
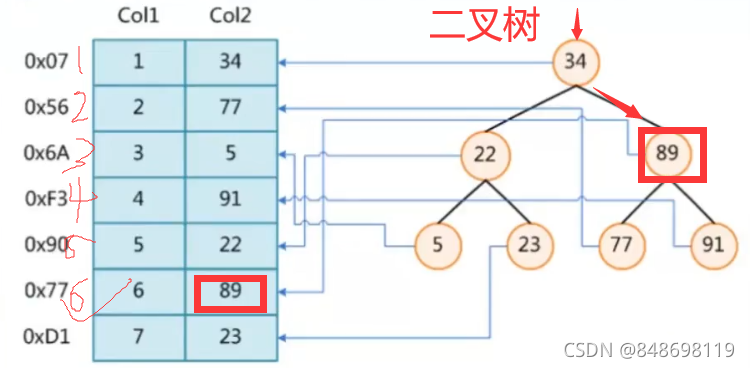
缺点
二叉树,插入大的元素总是放在我们的右下角,插小的元素放左下角,
把Col1当做索引时(当列数据是自增的),和全表扫描在性能上边没有太大的差别,而且还额外增加了索引的存储空间
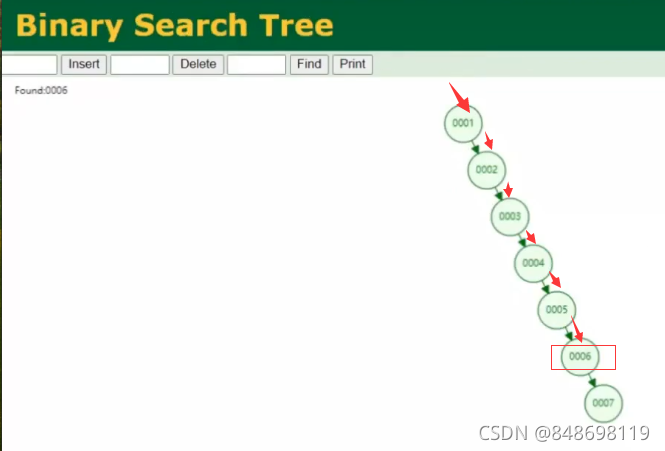
2.红黑树的优缺点
HashMap的底层实现就用到了红黑树。
优点
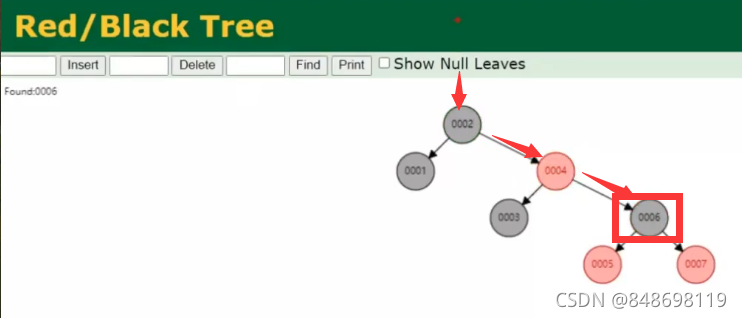
红黑树本质上也是二叉树,但是和二叉树不一样,他是二叉平衡树
它有自我平衡功能,如果一个树,一边比另外一边大的太多,它能够自动平衡,让一边与另外一边相差不要太多
 比单纯的二叉树查找次数缩短了一半,磁盘的I/O次数减少了一半
比单纯的二叉树查找次数缩短了一半,磁盘的I/O次数减少了一半
缺点
为什么MySQL最终没有选择红黑树呢?
红黑树当数据存储比较大的时候,由于它的树的高度不可控,导致在树的结构遍历元素的时候,如果到了叶子节点,那么需要查找很多次磁盘,性能就会非常低。这是MySQL没有选择红黑树的最主要的原因。
如何去优化?
如果是树进行存储的话,树的高度越小,查找的次数越少,性能效率就会有很大的提升
多路查找
分配索引节点存储的空间的时候,一次给它分配的大一点点,分配多一点点,一个节点可以放更多的索引元素,索引和索引之间还留一点空间做一些分叉,没一个分叉又可以放一点节点。同样存储500万条数据数的高度会更小(横向增多了)

这个优化的结构就是B-Tree
3.B-Tree
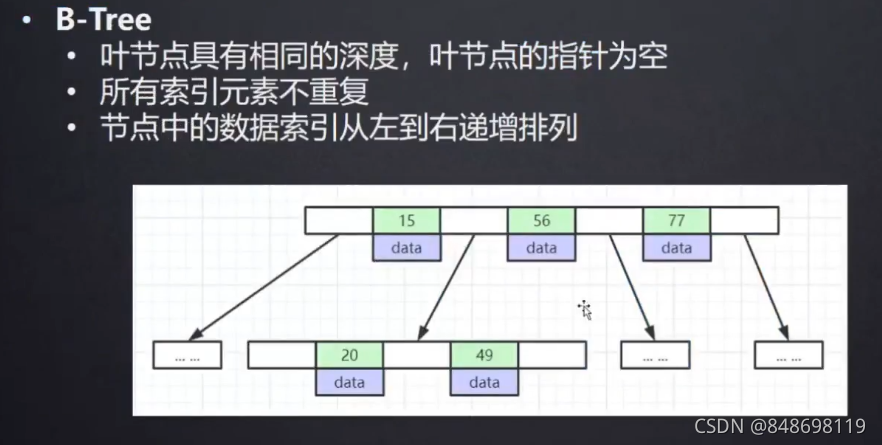
MySQL最终并没有用B-Tree,是在B-Tree上对整个数据结构做了一点点优化得到一个B+Tree(B-Tree变种)
4.B+Tree
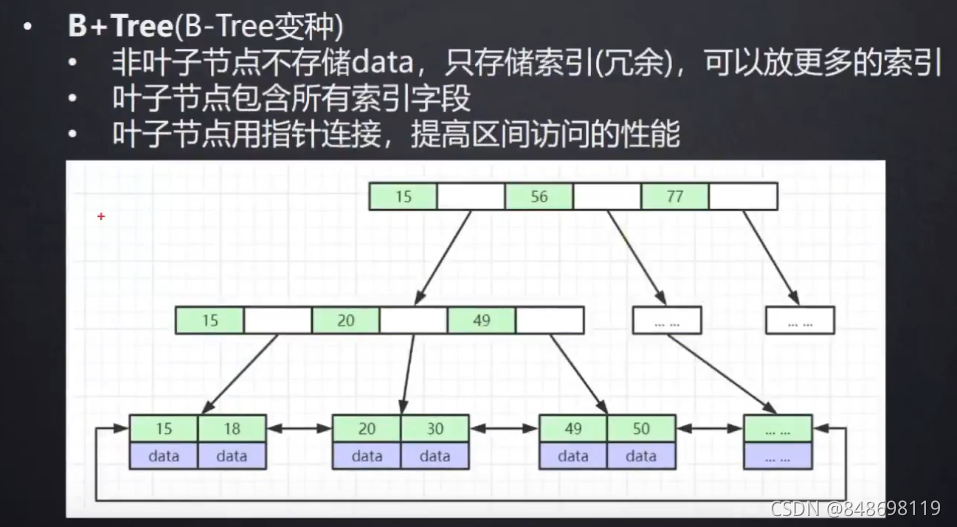 B+Tree是一个什么的结构呢?
B+Tree是一个什么的结构呢?
它会把整张表的所有的索引元素都放到叶子节点,叶子节点有整张表的所有的索引元素,非叶子节点是从每一个叶子索引节点拿的第一个元素,做冗余的索引,来组织这一颗B+Tree
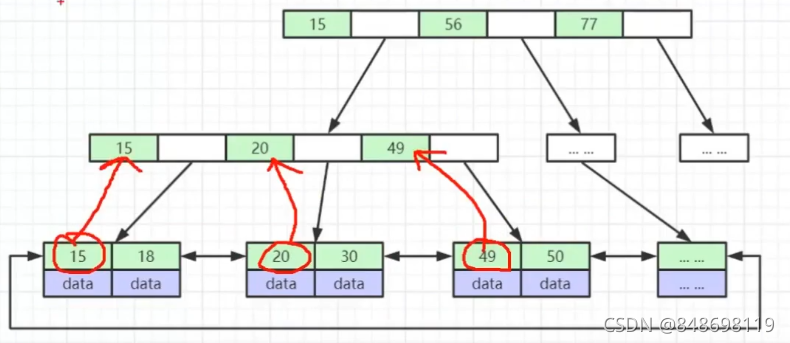
我们期望存储相同的元素,树的高度越小越好,MySQL底层的这个B+Tree存储索引的结构,它的容量大概是多少?
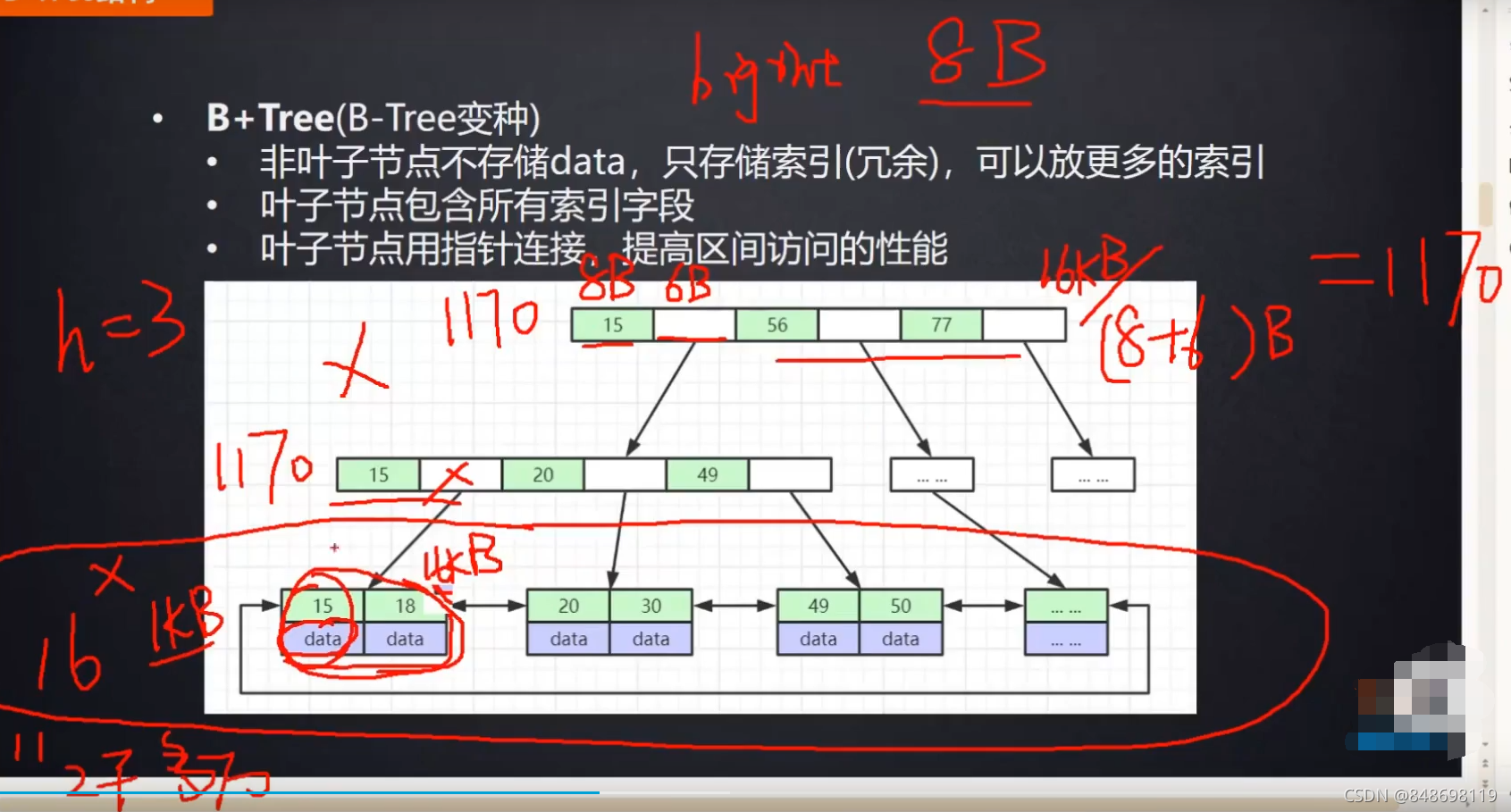
每一个节点默认设置16KB,整个树可以放两千多万条索引元素
B+Tree特点
有序性

元素从磁盘读到内存里去,相当于做磁盘I/O,磁盘I/O性能很低
内存中的折半查找是相当快的,与一个磁盘I/O的时间相比可以忽略不计,B+Tree非叶子结点,直接在MySQL初始化的时候,都已经加载到内存中去了,真正查找一个元素的时候,直接在内存中快速定位,也就是说整个过程中我们只需要1次的磁盘I/O,效率相当高。
哪怕上千万行的表记录
不是合理的走索引的话,这条SQL语句要执行几十秒(几千万行全部扫描需要几十秒)
合理的走索引性能提升几个数量级(可能扫描一条记录就搞定了,怎么扫的,前边都内存里快速匹配,然后通过树的结构快速定位到某个节点,磁盘上加载1次I/O就结束了,性能相当高)几毫秒,几十毫秒就查找到我们的元素了。
底层为什么查找这么快的原因
借助B+Tree结构的巧妙的设计

无需安装部署,在线快速体验 Byzer
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)