
内置 Estimator/Transformer 插件
Byzer 内置了非常多的 Estimator/Transformer 帮助用户去解决一些用 SQL 难以解决的问题。我们先来看看Estimator/Transformer 是什么。 通常而言,Estimator 会学习数据,并且产生一个模型。而 Transformer 则是纯粹的数据处理。通常我们认为算法是一个 Estimator,而算法训练后产生 的模
Byzer 内置了非常多的 Estimator/Transformer 帮助用户去解决一些用 SQL 难以解决的问题。我们先来看看Estimator/Transformer 是什么。
通常而言,Estimator 会学习数据,并且产生一个模型。而 Transformer 则是纯粹的数据处理。通常我们认为算法是一个 Estimator,而算法训练后产生 的模型则是 Transformer。大部分数据处理都是 Transformer,SQL 中的 select 语句也是一种特殊的 Transformer。
在接下来的章节里,我们介绍一些有趣而实用的 Estimator/Transformer,帮助大家更好的解决工作中的问题。
缓存表插件/CacheExt
用户能使用 Spark 的 cache 功能分布式缓存计算结果,但这存在一个问题:用户需要手动释放计算结果。
Byzer 为了解决这个问题,需要将缓存的生命周期进行划分:
-
script
-
session
-
application
默认缓存的生命周期是 script。随着业务复杂度提高,一个脚本其实会比较复杂,在脚本中我们存在反复使用原始表或者中间表、临时表的情况。这个时候我们可以通过 cache 实现:原始表被缓存,中间表只需计算一次,然后脚本一旦执行完毕,就会自动释放。使用方式也极度简单:
select 1 as a as table1;
!cache table1 script;
-- 等价于ET CacheExt 的用法
select * from table1 as output;使用 !cache 命令,可以将表 table1 设置为
上述代码也可以使用 run 语法,通过执行 ET 的方式实现。实际 ET 和 command 只是使用方式上面的不同,在Byzer-lang 内部实现使用的是相同的代码逻辑。
代码示例如下:
run table1 as CacheExt.`` where execute="cache" and lifeTime="script";
select * from table1 as output;session 级别暂时还没有实现。application 级别则是和 Byzer Engine 的生命周期保持一致。需要手动释放:
!uncache table1;或者使用run语法:
run table as CacheExt.`` where execute="uncache";表缓存功能极大的方便了用户使用 cache。对于内存无法放下的数据,系统会自动将多出来的部分缓存到磁盘。
CacheExt 的配置参数
| 参数名 | 参数含义 |
|---|---|
| execute | 是否开启 cache,可选值为:cache、uncache,默认为 cache |
| lifeTime | 设置缓存的生命周期,可选值为:script、session、application。默认为script级别 |
| isEager | 如果设置为 true,会立即进行缓存。cache ET 默认懒执行,该参数设置为 true 会立即执行,默认为 false |
Json 展开插件/JsonExpandExt
数据处理中,JSON 数据很常见的,例如埋点数据。Hive 和 Spark 均提供了 JSON 处理函数, 使用 Byzer 插件,可以方便地将一个 JSON 字段展开为多个字段。 下面以例子介绍其使用方式。
示例
- 查看帮助
load modelExample.`JsonExpandExt` AS output;- 例子1:JSON 没有嵌套
SELECT '{"name":"Michael"}' AS col_1
UNION ALL
SELECT '{"name":"Andy", "age":30}' AS col_1 AS table_1;
run table_1 as JsonExpandExt.`` where inputCol="col_1" AND samplingRatio = "1.0" as table_2;结果如下
| name | age |
|---|---|
| Michael | |
| Andy | 30 |
inputCol 表示 JSON 字段 col_1。samplingRatio 指系统采样分析 JSON 结构的采样率,为大于 0 小于 1 的小数。
- 例子2:嵌套的 JSON
SELECT '{"name":"Michael", "address":{"city":"hangzhou", "district":"xihu"} } ' AS col_1 AS table_1;
run table_1 as JsonExpandExt.`` where inputCol="col_1" AND samplingRatio = "1.0" as table_2;
run table_2 AS JsonExpandExt.`` WHERE inputCol="address" AS table_3;结果如下
| name | city | district |
|---|---|---|
| Michael | hangzhou | xihu |
本例子的 city 嵌套在第二层,因而需要执行两次 run 语句。
发送邮件插件/SendMessage
什么是 SendMessage ET ?
ET 是 Byzer 语言内置 Estimator/Transformer 的简称。
SendMessage 是我们常用的发送消息的 ET,目前支持邮件的方式。除此之外,我们还有一个单独的 ET(FeishuMessageExt)支持飞书消息,后续也会支持更多的 SNS 工具的消息交互。本节内我们先了解下邮件 ET 的使用方式。
使用场景示例:
- 数据计算处理后,生成下载链接,发邮件给相关人员
- 数据量较少的情况,可以直接发送数据处理结果
为什么选择 Byzer-lang ?
传统分析型的报表系统,开发流程非常长,需要较多人工维护成本和迭代成本。一般会有一个邮件服务,该服务会定制开发一套 DSL 语法,用于在交互层面方便用户在邮件模板中使用,如:查询 SQL、调度周期语法糖、自定义参数、公共参数等。然后会有一个调度框架周期性触发邮件任务计算。
我们发现上述流程非常复杂,那有没有快速简洁的方式,无需多方合作,无需定制化开发,就能完成一个企业级可复用的邮件服务工具呢? 这时 Byzer-lang 的优势便体现出来了。只需几行代码,就能完成上述复杂的流程。
接下来让我们结合一个 nginx 日志分析的场景来看看 Byzer-lang 是如何高效简洁地完成上述的报表开发和邮件服务任务的。
I. 配置参数
了解参数具体含义,方便我们在后续代码中使用 SendMessage 把分析好的 PV 报表用邮件的方式发送出去。
红色字体参数为必填项。
| 参数名 | 参数含义 |
|---|---|
| method | 消息发送方式,目前支持:MAIL(邮件发送);默认值为MAIL |
| mailType | 邮件服务类型,目前支持:local(使用本地sendmail服务)、config(sql配置SMTP服务器);默认值为 config |
| userName | 邮箱服务用户名,即邮箱账号,如:do_not_reply@gmail.com;如果为config模式该值必填。 |
| password | 邮箱服务授权码;如果为config模式该值必填。 |
| from | 发件人邮箱账户 |
| to | 收件人邮箱账户,多个账户使用','分隔 |
| cc | 抄送人邮箱账户,多个账户使用','分隔 |
| subject | 邮件标题 |
| content | 邮件内容 |
| contentType | 邮件内容的格式,目前支持标准的Java Mail Content-Type,如:text/plain、text/html、text/csv、image/jpeg、application/octet-stream、multipart/mixed |
| attachmentContentType | 邮件附件内容的格式,目前支持标准的Java Mail Content-Type |
| attachmentPaths | 邮件附件地址,多个地址使用','分隔 |
| smtpHost | SMTP邮件服务域名;如果为config模式该值必填。 |
| smtpPort | SMTP邮件服务端口号;如果为config模式该值必填。 |
| properties.[邮件客户端配置] | javaMail邮件客户端配置,常用配置如:properties.mail.debug、properties.mail.smtp.ssl.enable、properties.mail.smtp.ssl.enable、properties.mail.smtp.starttls.enable等 |
发送邮件使用 run 语法,我们目前支持 2 种方式,分别如下:
- local: 连接本地 sendmail 服务器的方式。需要用户在本地服务器部署 sendmail 服务,并配置好用户名、授权码等信息,在byzer中会连接本地服务发送邮件。通过 sendmail 服务我们可以灵活的选择 MDA(邮件投递代理)或者 MTA(邮件服务器)来处理邮件。
- config: 配置 SMTP 服务器的方式。在 Byzer 中配置邮箱用户名和邮箱授权码、邮箱 SMTP 服务器地址、端口,通过授权码登录第三方客户端邮箱。如果使用个人或者企业邮箱推荐使用该方式。
在 Byzer config 模式中,使用的邮件用户代理( Mail User Agent, 简称 MUA )客户端程序是 JavaMail-API。
II、获取邮箱授权码(password)
1. 什么是授权码?
授权码是用于登录第三方客户端的专用密码。
适用于登录以下服务:POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务。
注意:大部分邮件服务为了你的帐户安全,更改账号密码会触发授权码过期,需要重新获取新的授权码登录。
2. 为什么需要邮箱授权码(password)
使用客户端连接邮箱 SMTP 服务器时,可能存在邮件泄露风险,甚至危害操作系统的安全,大部分邮件服务都需要我们提供授权码,验证用户身份,用于登录第三方客户端邮箱发送邮件。
不同邮箱获取授权码的方式不同,我们以QQ邮箱为例,首先访问 设置 - 账户 - POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务,然后找到下图所示的菜单,开启 POP3/SMTP 服务,并点击生成授权码。

3. 如何获取 smtpHost、smtpPort
不同邮箱获取授权码的方式不同,我们可以很容易在用户手册中找到邮箱提供的SMTP服务器。以QQ邮箱为例,QQ邮箱 POP3 和 SMTP 服务器地址设置如下:
| 类型 | 服务器名称 | 服务器地址 | 非SSL协议端口号 | SSL协议端口号 | TSL协议端口 |
|---|---|---|---|---|---|
| 发件服务器 | SMTP | smtp.qq.com | 25 | 465 | 587 |
| 收件服务器 | POP | pop.qq.com | 110 | 995 | - |
| 收件服务器 | IMAP | imap.qq.com | 143 | 993 | - |
如果使用的是163邮箱,则相关服务器信息:
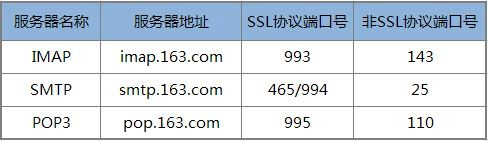
注意:每个邮件厂商的smtp服务都有自己的实现,不同的厂商端口号对应的协议可能不同,比如端口587,在qq中使用的TSL协议,而在163中使用的是SSL协议,请以官方使用说明为准。
III. 如何使用
在开始开发一个 PV 统计任务之前,我们先看一个简单的 config 方式的代码示例,仅需 10 行左右的配置代码就可以完成数据结果的在线邮件推送:
set EMAIL_TITLE = "这是邮件标题"; set EMAIL_BODY = "Byzer 任务 xx 运行完成,请及时查询结果"; set EMAIL_TO = "userAccountNumber@qq.com, userAccountNumber@163.com"; -- 使用配置账号的方式 run command as SendMessage.`` where method = "mail" and from = "userAccountNumber@qq.com" and to = "${EMAIL_TO}" and subject = "${EMAIL_TITLE}" and content = "${EMAIL_BODY}" and smtpHost = "smtp.qq.com" and smtpPort = "587" -- 设置邮件客户端的协议为 SSL 协议,默认为 SSL 协议,也可选择 TLS 配置: --`properties.mail.smtp.starttls.enable`= "true" and `properties.mail.smtp.ssl.enable`= "true" and userName = "userAccountNumber@qq.com" and password="***" ;其中,userAccountNumber 代表用户邮箱账号。
我们也支持使用本地邮件服务的方式,方式如下:
run command as SendMessage.`` where method = "mail" and mailType="local" and content = "${EMAIL_BODY}" and from = "yourMailAddress@qq.com" and to = "${EMAIL_TO}" and subject = "${EMAIL_TITLE}" ;同时,SendMessage 还支持使用邮件发送 HTML 格式的文本,并携带附件。
示例如下:
1) 首先通过 Byzer Notebook 上传 2 个 CSV 文件employee.csv和company.csv,作为附件内容。
2) 通过如下 SQL 的方式发送该邮件
set EMAIL_TITLE = "这是邮件标题"; set EMAIL_BODY = '''<div>这是第一行</div><br/><hr/><div>这是第二行</div>'''; set EMAIL_TO = "yourMailAddress@qq.com"; run command as SendMessage.`` where method="mail" and content="${EMAIL_BODY}" and from = "yourMailAddress@qq.com" and to = "${EMAIL_TO}" and subject = "${EMAIL_TITLE}" and contentType="text/html" and attachmentContentType="text/csv" and attachmentPaths="/tmp/employee.csv,/tmp/employee.csv" and smtpHost = "smtp.qq.com" and smtpPort="587" and `properties.mail.smtp.starttls.enable`= "true" and `userName`="yourMailAddress@qq.com" and password="---" ;IV. 完整 Example 示例
模拟需求为:统计 Byzer 官网不同页面的访问 PV,取 TOP 10,统计结果通过邮件附件的方式发送到指定邮箱。
Step1、测试数据集
首先,我们准备好一份演示使用的 nginx 模拟日志文件,文本内容如下:
127.0.0.1 - _ - [11/Sep/2021:17:42:36 +0000] "\x05\x01\x00" 400 157 "-" "-" "-" 127.0.0.1 - docs.byzer.org - [11/Sep/2021:17:42:43 +0000] "GET https://docs.byzer.org/ HTTP/1.1" 403 153 "-" "curl/7.58.0" "-" 127.0.0.1 - 127.0.0.1 - [11/Sep/2021:18:17:38 +0000] "GET /phpmyadmin4.8.5/index.php HTTP/1.1" 403 555 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3464.0 Safari/537.36" "-" 127.0.0.1 - www.byzer.org - [11/Sep/2021:18:26:31 +0000] "GET / HTTP/1.1" 200 2343 "-" "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36" "-" 127.0.0.1 - www.byzer.org - [11/Sep/2021:18:26:32 +0000] "GET /static/css/main.736717e4.chunk.css HTTP/1.1" 200 4273 "http://www.byzer.org/" "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36" "-" 127.0.0.1 - www.byzer.org - [11/Sep/2021:18:26:32 +0000] "GET /static/js/main.35f9529f.chunk.js HTTP/1.1" 200 21286 "https://www.byzer.org/" "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36" "-" 127.0.0.1 - 127.0.0.1 - [11/Sep/2021:17:44:24 +0000] "HEAD http://127.0.0.1/ HTTP/1.1" 400 0 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36" "-"可以将上面的文本复制到本地并保存成一份 text 文件,我们命名为:access_log.txt。
Step2、上传数据
下面会通过 Byzer Notebook 的数据目录中的上传功能,上传我们的 access_log.txt 日志文件。
Byzer Notebook 注册试用入口:https://www.byzer.org/home
点击顶栏中的主页,再点击上传:
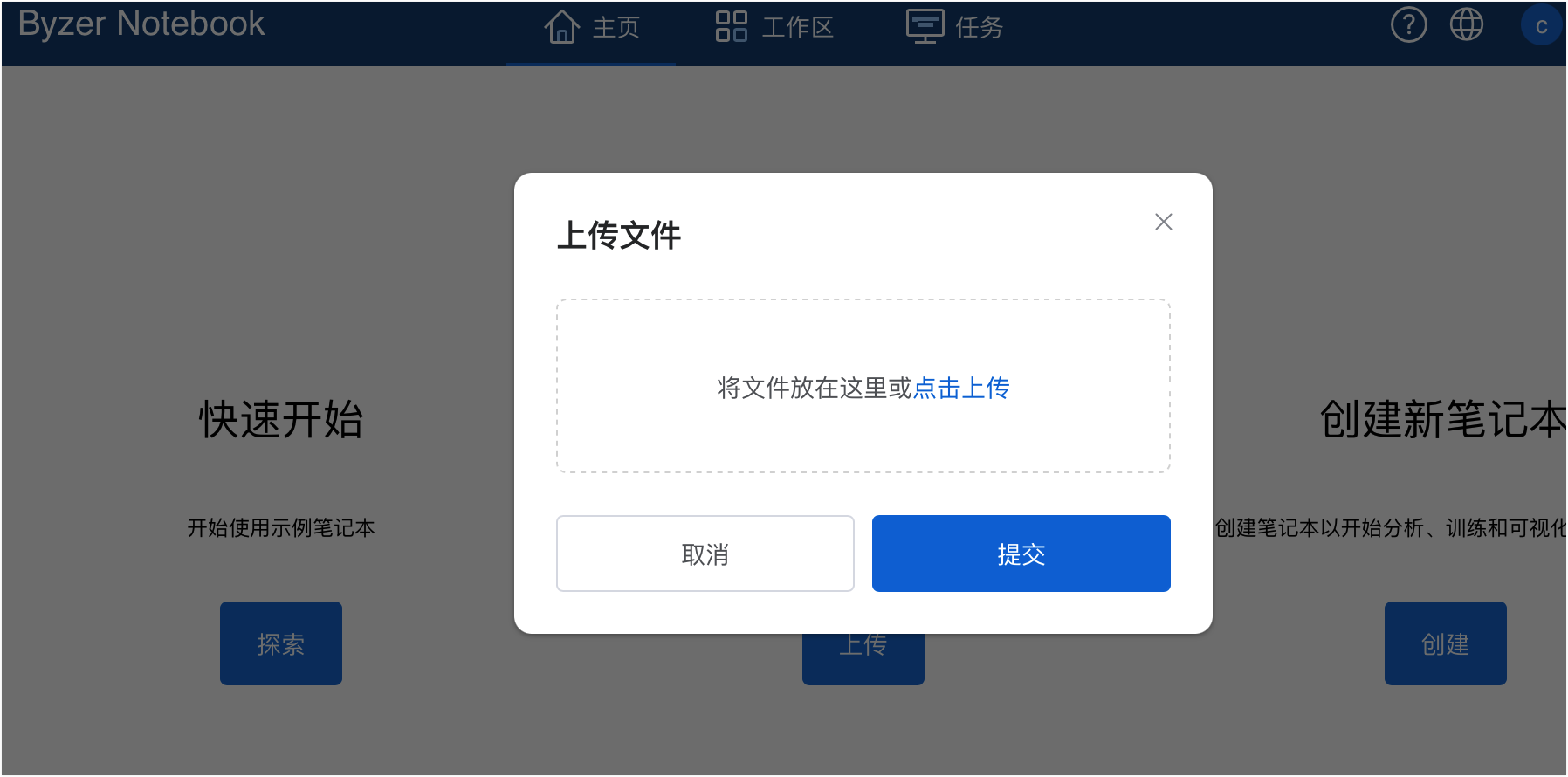
将文件拖拽到上传框后,点击提交就可以了。上传成功后,您可以通过命令行查看上传的文件,也可以进入工作区,找到侧边栏中的数据目录模块,在 File System 中查看:
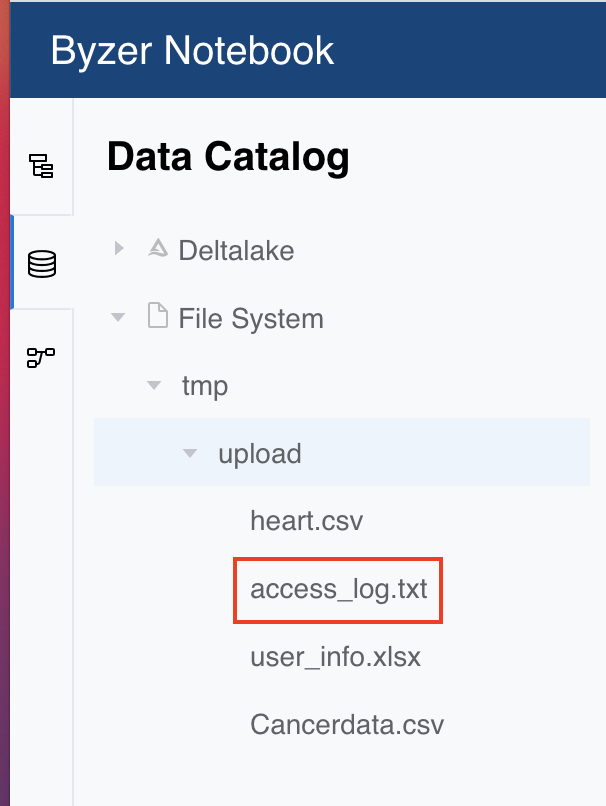
可以看到,我们上传的文件已经在 /tmp/upload 里了。
需要注意的是,我们的 FileSystem 并不是本地路径的概念,/tmp/upload 是一个相对路径,而 FileSystem 是对文件系统的封装,用于适配不同的文件系统。其绝对地址是由内置的数据湖配置(streaming.deltalake.path)决定的,Engine 端可以根据数据湖路径位置,使用本地存储系统,也可以在 spark/conf 里设置 hdfs-site.xml 等配置文件,配置远程存储,亦或是使用 Juicefs 挂载任意对象存储。
Step3、开发邮件任务
load text.`/tmp/upload/access_log.txt` as nginxTable; -- 日志文件的清洗和统计 select access_host,access_page,count(1) as access_freq from ( select split(value,' ')[2] as access_host,split(value,' ')[7] as access_page from (select * from nginxTable where value is not null) ) where access_host !="-" group by access_host,access_page order by access_freq desc limit 10 as accessTable; set saveDir="/tmp/access"; set savePath="/tmp/access.csv"; -- 保存PV统计数据为CSV格式的文件 save overwrite accessTable as csv.`${saveDir}` where header="true"; -- 因为在分布式环境运行,我们的文件会按照分区个数保存为多个文件,这里我们进行合并 !hdfs -getmerge /tmp/access/tmp/access.csv; set EMAIL_TITLE = "Byzer网站访问日志分析"; set EMAIL_BODY = '''<div>Hi All,<br/><br/> 日志分析完成,请查收邮件!</div><br/><hr/><div>Thanks,<br/>The Byzer Org</div>'''; set EMAIL_TO = "userAccountNumber@qq.com, userAccountNumber@163.com"; -- 发送附件邮件到指定邮箱 run command as SendMessage.`` where method="mail" and content="${EMAIL_BODY}" and from = "userAccountNumber@qq.com" and to = "${EMAIL_TO}" and subject = "${EMAIL_TITLE}" and contentType="text/html" and attachmentContentType="text/csv" and attachmentPaths="${savePath}" and smtpHost = "smtp.qq.com" and smtpPort="587" and `properties.mail.smtp.ssl.enable`= "true" and `userName`="userAccountNumber@qq.com" and password="***" ;上面的代码应该还是非常清晰易懂的,具体流程解释如下:
-
首先加载前面上传好的日志文件,在第4行中进行日志文件的清洗和统计,这里我们使用了比较简单的 split 的方式,实际会有更加复杂的情况,Byzer-lang 提供了 python 脚本,ET,UDF 等能力给予用户,方便其实现更加适合复杂数据的清洗逻辑。
-
在第16行中使用 set 语法设置一个变量,为统计结果的输出地址,然后我们可以用 save 语法将 csv 文件保存到数据湖中。由于任务在计算的时候会产生多个分区,保存到数据湖会有多个文件,我们使用宏命令
!hdfs将数据进行合并。 -
第29行中,使用SendMessage发送邮件到QQ邮箱,通过
attachmentPaths="${savePath}"设置附件内容。 -
最后,我们设置一下 SMTP 协议使用的相关参数,完成邮件的发送。
Step4、邮件发送完毕,验证结果
我们来看下实际发送的邮件,是不是我们预期的效果。
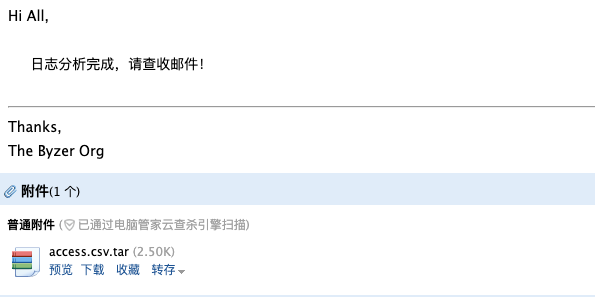
可以看到,我们已经成功地通过 Byzer Notebook 将分析结果发送到了对应的邮箱!
我们从模拟测试数据中,统计到了 PV TOP 10 的页面:
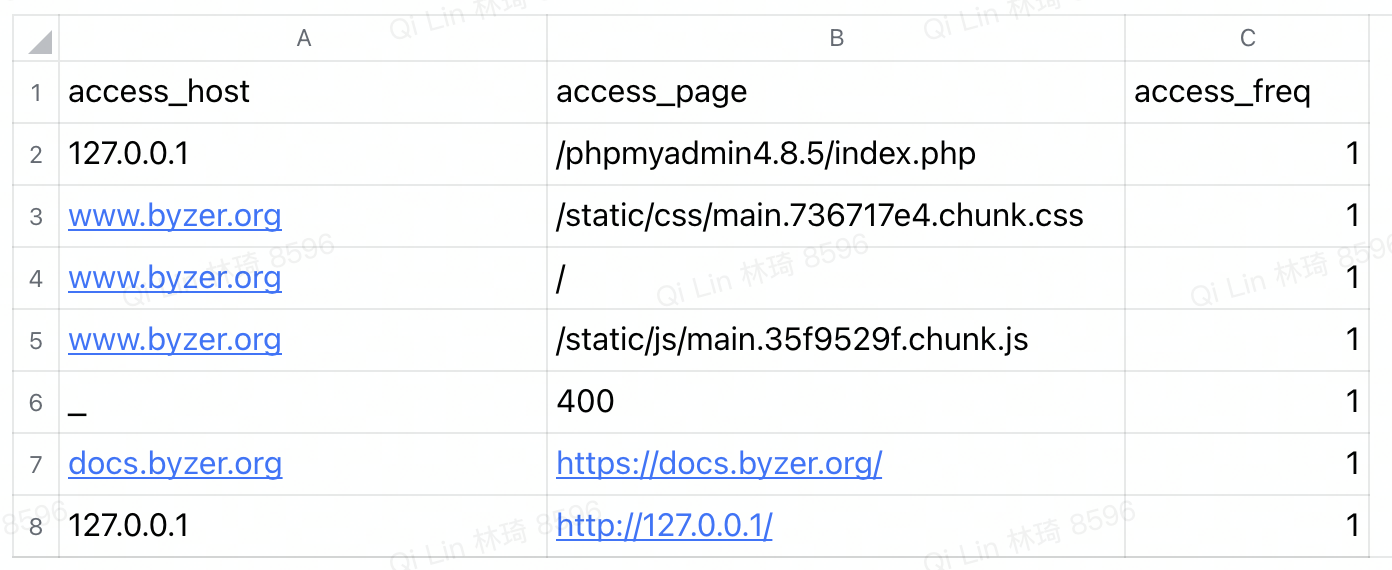
使用上述的教程,我们轻松地完成了从 数据导入->数据清洗->数据分析->数据导出->邮件发送 的全流程。由此我们可以衍生同类型的应用方式,即通过 load 抽取某个或多个数据源中的数据,结合 Byzer Notebook 即将集成的调度能力,就可以高效地产出一个企业级的自动化报表系统。
语法解析插件/SyntaxAnalyzeExt
我们知道 Byzer 支持语法解析接口,我们可以通过设置参数 executeMode 为 analyze,实现 Byzer 语法的解析。语法解析接口对 set/load 语法解析比较充分,但是 select 语句解析的比较粗糙,只有 raw,sql,tableName 三个部分。在很多场景里面,我们其实需要解析出 SQL 中所有的表,而不仅仅是这条 SQL 中生成的表,我们可以通过 SyntaxAnalyzeExt 来完成表的抽取。
使用场景示例:
- 我们需要知道一个 select 语句的所有输入源表
语法解析使用 run 语法,其中 where 子句中,action为解析的类型,目前仅支持抽取表功能extractTables,也是该 ET 中action的缺省值,sql为待解析的 SQL 语句,格式为标准的 Spark SQL,使用方式如下:
run command as SyntaxAnalyzeExt.`` where
action="extractTables" and sql='''
select a from table1 as output;
''';下面给一个完整的例子: 首先生成两个表,table1 和 table2。然后执行SyntaxAnalyzeExt抽取一个嵌套的 SQL 的所有的表。 如下:
select "stub" as table1;
select "stub" as table2;
run command as SyntaxAnalyzeExt.`` where
action = "extractTables" and sql='''
select * from (select * from table1 as c) as d left join table2 as e on d.id=e.id
''' as extractedTables;
select * from extractedTables as output;结果如下:
+----------+
|tableName |
+----------+
|table1 |
|table2 |
+----------+另外,我们也支持把 SQL 通过变量方式传入,方式如下:
select "test" as col1 as table1;
set test_sql = '''select * from table1 as output''';
run command as SyntaxAnalyzeExt.`` where
action = "extractTables" and sql="${test_sql}" as extractedTables;
select * from extractedTables as output1;接着就可以使用!执行这个变量。
!test_sql;
表分区插件/TableRepartition
很多时候,我们需要改变分区数,比如保存文件之前,或者我们使用 python,我们希望 python worker 尽可能的并行运行,这个时候就需要 TableRepartition 的帮助了。
TableRepartition 支持 run 语法执行,也支持使用 Byzer 宏命令,下面将详细介绍两种使用方式。
使用 ET 方式执行
run 语法执行方式如下:
run [表名] as TableRepartition.`` where partitionNum=[分区数] as [输出表名];配置参数
| 参数名 | 参数含义 |
|---|---|
| partitionNum | 重新分区的分区数 |
| partitionType | 重新分区的分区类型,现支持:hash、range |
| partitionCols | 重新分区使用的列,当 partitionType 为 range 类型时,partitionCols 必须指定;shuffle为 false 时不允许指定 |
| shuffle | 重新分区时是否开启 shuffle。true 为开启,false为关闭 |
示例1:partitionNum 的使用
加载一份 JSON 数据到 data 表:
set jsonStr = '''
{"id":0,"parentId":null}
{"id":1,"parentId":null}
{"id":2,"parentId":1}
{"id":3,"parentId":3}
{"id":7,"parentId":0}
{"id":199,"parentId":1}
{"id":200,"parentId":199}
{"id":201,"parentId":199}
''';
load jsonStr.`jsonStr` as data;对 data 表重分区2个分区,如下所示:
run data as TableRepartition.`` where partitionNum=2
as newdata;示例2:partitionType 的使用
partitionType 支持如下2种配置:
-
hash:repartition 应用
HashPartitioner,目的是在提供的分区数上均匀地分布数据。如果提供了一列(或更多列),这些值将被散列,并通过计算partition = hash(columns) % numberOfPartitions来确定分区号。 -
range:repartition 应用
RangePartitioner,将根据列值的范围对数据进行分区。这通常用于连续(非离散)值,如任何类型的数字。
下面通过一些 Demo 来演示这种差异。
1)Test Dataframes
在这个 Demo 中使用以下 JSON 数据:
set jsonStr = '''
{"id":0,"parentId":null}
{"id":1,"parentId":null}
{"id":2,"parentId":1}
{"id":3,"parentId":3}
{"id":7,"parentId":0}
{"id":199,"parentId":1}
{"id":200,"parentId":199}
{"id":201,"parentId":199}
''';
load jsonStr.`jsonStr` as data;
所有测试结果都使用如下取数逻辑(该SQL应放在TableRepartition语句之后用于取数):
!profiler sql '''
select spark_partition_id() as partition,min(id) as min_id,max(id) as max_id,count(id) as count
from simpleData
group by partition
order by partition; ''' ;2)partitionType="hash"
示例代码如下:
run data as TableRepartition.`` where partitionNum="3" and partitionType="hash" as simpleData;正如预期的那样,我们得到了3个分区,id被散列到不同的分区,结果如下:
| partition | min_id | max_id | count |
|---|---|---|---|
| 0 | 2 | 7 | 3 |
| 1 | 0 | 0 | 1 |
| 2 | 1 | 201 | 4 |
3)partitionType="range"
示例代码如下:
run data as TableRepartition.`` where partitionNum="3" and partitionType="range" and partitionCols="id" as simpleData;同样在本例中,我们得到了3个分区,但这次最小值和最大值清楚地显示了分区中的值的范围,结果如下:
| partition | min_id | max_id | count |
|---|---|---|---|
| 0 | 0 | 2 | 3 |
| 1 | 3 | 199 | 3 |
| 2 | 200 | 201 | 2 |
使用宏命令方式执行
宏命令方式执行方式如下:
!tableRepartition _ -i [表名] -num [分区数] -o [输出表名];下面看一个示例,如果需要对表 table_cc 重分区为2个分区,输出表为 newcc,可使用如下命令:
!tableRepartition _ -i table_cc -num 2 -o newcc;计算表父子关系插件/TreeBuildExt
在 SQL 中计算父子关系无疑是复杂的,需要复杂的 join 关联,通常而言,用户计算父子关系,一般需要:
- 任意一个指定节点的所有子子孙孙节点。
- 任意一个指定节点树状层级
- 返回一个一个或者多个树状结构
假设我们要处理的数据格式如下:
set jsonStr = '''
{"id":0,"parentId":null}
{"id":1,"parentId":null}
{"id":2,"parentId":1}
{"id":3,"parentId":3}
{"id":7,"parentId":0}
{"id":199,"parentId":1}
{"id":200,"parentId":199}
{"id":201,"parentId":199}
''';可以看出上表存在父子关系。
在许多运营或市场推广裂变计算的场景中,常常需要统计用户的邀请人数和相应邀请链的深度,则可以使用这个插件快速统计完成。
假设现想计算指定节点 7 有多少子节点以及其所属的层级,则相应的操作方式如下:
首先,我们把这个数据映射成表,使用 load 语法加载我们的 json 数据。
load jsonStr.`jsonStr` as data;如果您当前使用的是 spark3 版本(Byzer 中默认为 spark3 ),则需要设置以下参数:
set spark.sql.legacy.allowUntypedScalaUDF=true where type="conf";然后便可以用 run 指令使用该模块了:
run data as TreeBuildExt.``
where idCol="id"
and parentIdCol="parentId"
and treeType="nodeTreePerRow"
as result;结果如下:
+---+-----+------------------+
|id |level|children |
+---+-----+------------------+
|200|0 |[] |
|0 |1 |[7] |
|1 |2 |[200, 2, 201, 199]|
|7 |0 |[] |
|201|0 |[] |
|199|1 |[200, 201] |
|2 |0 |[] |
+---+-----+------------------+level 是层级,children 则是所有子元素(包括子元素的字元素)。
您还可以直接生成 N 棵树,然后您可以使用自定义 udf 函数继续处理这棵树:
run data as TreeBuildExt.``
where idCol="id"
and parentIdCol="parentId"
and treeType="treePerRow"
as result;结果如下:
+----------------------------------------+---+--------+-----+
|children |id |parentID|level|
+----------------------------------------+---+--------+-----+
|[[[], 7, 0]] |0 |null |1 |
|[[[[[], 200, 199]], 199, 1], [[], 2, 1]]|1 |null |2 |
+----------------------------------------+---+--------+-----+children 是一个嵌套 row 结构,可以在 udf 里很好地被处理。
CacheExt 的配置参数
| 参数名 | 参数含义 |
|---|---|
| idCol | 必填项,节点 id 使用的字段 |
| parentIdCol | 必填项,parent 节点 id 使用的字段 |
| recurringDependencyBreakTimes | 最高级别应低于此值; 当遍历一棵树时,一旦发现一个节点两次,则该子树将被忽略 |
| topLevelMark | 指定首层 id |
| treeType | 如果设置为 true,会立即进行缓存;cache ET 默认懒执行,该参数设置为 true 会立即执行,默认为 false |
将字符串当做代码执行
作用
run-script 插件用于将字符串当做 byzer 脚本执行。 如果 Byzer Meta Store 采用了 MySQL 存储,那么你需要使用 https://github.com/byzer-org/byzer-extension/blob/master/stream-persist/db.sql 中的表创建到该 MySQL 中。
使用示例
set code1='''
select 1 as a as b;
''';
-- 使用宏命令 runScript 执行一个 byzer 代码
!runScript '''${code1}''' named output;
JDBC 插件(内置)
为了方便用户直接操作数据库,执行 Query/DDL 语句,Byzer 内置了一个插件。
DDL 模式
run command as JDBC.`` where
sqlMode="ddl"
and driver="com.mysql.jdbc.Driver"
and url="jdbc:mysql://127.0.0.1:3306/wow?useSSL=false&haracterEncoding=utf8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false"
and user="root"
and password="xxxxx"
and `driver-statement-0`='''
create table xxxx
(
id int,
name string
)
''';其中,driver-statement-<序号> 是一个 DDL 语句。 你可以填写多个,比如,driver-statement-0,driver-statement-1 等。 系统会按照最后的序号执行。
Query 模式
run command as JDBC.`` where
sqlMode="query"
and driver="com.mysql.jdbc.Driver"
and url="jdbc:mysql://127.0.0.1:3306/wow?useSSL=false&haracterEncoding=utf8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false"
and user="root"
and password="xxxxx"
and `driver-statement-query`='''
select * from xxxx
'''
as newTable;
select * from newTable as output;注意,这里的 driver-statement-query 是一个 Query 语句,而不是 DDL 语句,名字也和 DDL 模式下有所区别。

无需安装部署,在线快速体验 Byzer
更多推荐
 0
0 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)