
外置 Estimator/Transformer 插件
Connect 语句持久化 connect-persist用于持久化connect语句。当系统重启后,无需再执行connect语句。 如何安装 如果Byzer Meta Store 采用了MySQL存储,那么你需要使用https://github.com/byzer-org/byzer-extension/blob/master/connect-persist/db.s
Connect 语句持久化
connect-persist 用于持久化connect语句。当系统重启后,无需再执行connect语句。
如何安装
如果Byzer Meta Store 采用了MySQL存储,那么你需要使用 https://github.com/byzer-org/byzer-extension/blob/master/connect-persist/db.sql 中的表创建到该MySQL存储中。
完成如上操作之后,安装插件:
!plugin app add - 'connect-persist-app-3.0';注意:示例中 byzer 的 spark 版本为 3.0 ,如果需要在 spark 2.4 的版本运行,请将安装的插件设置为
connect-persist-app-2.4
如何使用
!connectPersist;所有执行过的connect语句都会被保留下来。当系统重启后,会重新执行。 接下来我们看一个具体的例子。
-- 连接客户端byzer的数据库notebook,取别名为db1
connect jdbc where
url="jdbc:mysql://127.0.0.1:3306/notebook?useUnicode=true&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&autoReconnect=true&failOverReadOnly=false"
and driver="com.mysql.jdbc.Driver"
and user="root"
and password="root"
as db1;
持久化该connect连接
!connectPersist;重启byzer-lang引擎,我们可以在后台日志中看到持久化的连接被打印出来:
21/12/15 22:24:37 INFO PluginHook: Register App Plugin connect-persist-app-3.0 in tech.mlsql.plugins.app.ConnectPersistApp
21/12/15 22:24:38 INFO ConnectPersistApp: load connect statement format: jdbc db:db1启动后执行下面语句:
load jdbc.`db1.mlsql_job` as newtable;
select * from newtable as output limit 1;可以看到成功查询到了数据,db1连接已经被持久化。
| id | name | user | cell_list |
|---|---|---|---|
| 27 | 03_Demo_Notebook2 | zepp | [ 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131 ] |
使用 MySQL 存储元信息
前面我们提到,byzer Meta Store 可以采用MySQL存储,具体使用方式,请参考:byzer元信息存储
Byzer 断言
Byzer 断言 插件提供了在表中使用 assert 断言命令,用于判断 byzer 的结果表中数据是否符合预期。
如何安装
在 web console 中执行以下命令:
!plugin app add - "mlsql-assert-3.0";注意:示例中 byzer 的 spark 版本为 3.0 ,如果需要在 spark 2.4 的版本运行,请将安装的插件设置为
mlsql-assert-2.4
如何使用
-- 创建测试数据
set jsonStr='''
{"features":[5.1,3.5,1.4,0.2],"label":0.0},
{"features":[5.1,3.5,1.4,0.2],"label":1.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[4.4,2.9,1.4,0.2],"label":0.0}
{"features":[5.1,3.5,1.4,0.2],"label":1.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[4.7,3.2,1.3,0.2],"label":1.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
''';
load jsonStr.`jsonStr` as data;
select vec_dense(features) as features ,label as label from data
as data1;
-- 使用 RandomForest
train data1 as RandomForest.`/tmp/model` where
-- 一旦设置为 true,每次运行此脚本时,byzer 都会为您的模型生成新目录
keepVersion="true"
-- 指定测试数据集,该数据集将用于提供评估器以生成一些指标,例如:F1, Accurate
and evaluateTable="data1"
-- 设置 group 0 参数
and `fitParam.0.labelCol`="features"
and `fitParam.0.featuresCol`="label"
and `fitParam.0.maxDepth`="2"
-- 设置 group 1 参数
and `fitParam.1.featuresCol`="features"
and `fitParam.1.labelCol`="label"
and `fitParam.1.maxDepth`="10"
as model_result;
select name,value from model_result where name="status" as result;
-- 确保所有模型的状态都是成功的
!assert result ''':value=="success"''' "all model status should be success";如果最终执行结果的 value 不是 "success",则会在 Console 显示异常信息如下:
all model status should be success
java.lang.RuntimeException: all model status should be success
tech.mlsql.plugins.assert.ets.Assert.train(Assert.scala:93)
tech.mlsql.dsl.adaptor.TrainAdaptor.parse(TrainAdaptor.scala:102)
streaming.dsl.ScriptSQLExecListener.execute$1(ScriptSQLExec.scala:368)
streaming.dsl.ScriptSQLExecListener.exitSql(ScriptSQLExec.scala:407)
streaming.dsl.parser.DSLSQLParser$SqlContext.exitRule(DSLSQLParser.java:296)
org.antlr.v4.runtime.tree.ParseTreeWalker.exitRule(ParseTreeWalker.java:47)
org.antlr.v4.runtime.tree.ParseTreeWalker.walk(ParseTreeWalker.java:30)
org.antlr.v4.runtime.tree.ParseTreeWalker.walk(ParseTreeWalker.java:28)
streaming.dsl.ScriptSQLExec$._parse(ScriptSQLExec.scala:159)
streaming.dsl.ScriptSQLExec$.parse(ScriptSQLExec.scala:146)
streaming.rest.RestController.$anonfun$script$1(RestController.scala:136)
tech.mlsql.job.JobManager$.run(JobManager.scala:74)
tech.mlsql.job.JobManager$$anon$1.run(JobManager.scala:91)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
java.lang.Thread.run(Thread.java:748)Byzer mllib
byzer mllib 插件将 spark-mllib 包装为 byzer ET 使用。
如何安装
- 在 Web 控制台中执行以下命令:
!plugin app add "tech.mlsql.plugins.mllib.app.MLSQLMllib" "mlsql-mllib-3.0";注意:示例中 byzer 的 spark 版本为 3.0 ,如果需要在 spark 2.4 的版本运行,请将安装的插件设置为
mlsql-mllib-2.4
检查是否安装成功,可以执行如下宏命令,用于查看ET组件的信息:
!show et/ClassificationEvaluator;
!show et/RegressionEvaluator;- 手动安装
您也可以手动安装,首先,在你的终端中构建 shade jar:
pip install mlsql_plugin_tool
mlsql_plugin_tool build --module_name mlsql-mllib --spark spark243然后更改 byzer 引擎的启动脚本,添加jar包:
--jars YOUR_JAR_PATH在byzer中注册类:
-streaming.plugin.clzznames tech.mlsql.plugins.mllib.app.MLSQLMllib如果有多个类,请使用逗号分隔它们。 例如:
-streaming.plugin.clzznames classA,classB,classC如何使用
Classification:
predict data as RandomForest.`<your model HDFS path>` as predicted_table;
run predicted_table as ClassificationEvaluator.``;Regression:
predict data as LinearRegressionExt.`<your model HDFS path>` as predicted_table;
run predicted_table as RegressionEvaluator.``;更多 mllib 插件:
- 唯一标识符算子
- 频数分布算子
shell 命令插件
byzer shell 插件在 byzer engine 端提供 shell 宏命令,用于将 shell 脚本作为 byzer 代码的一部分来执行。
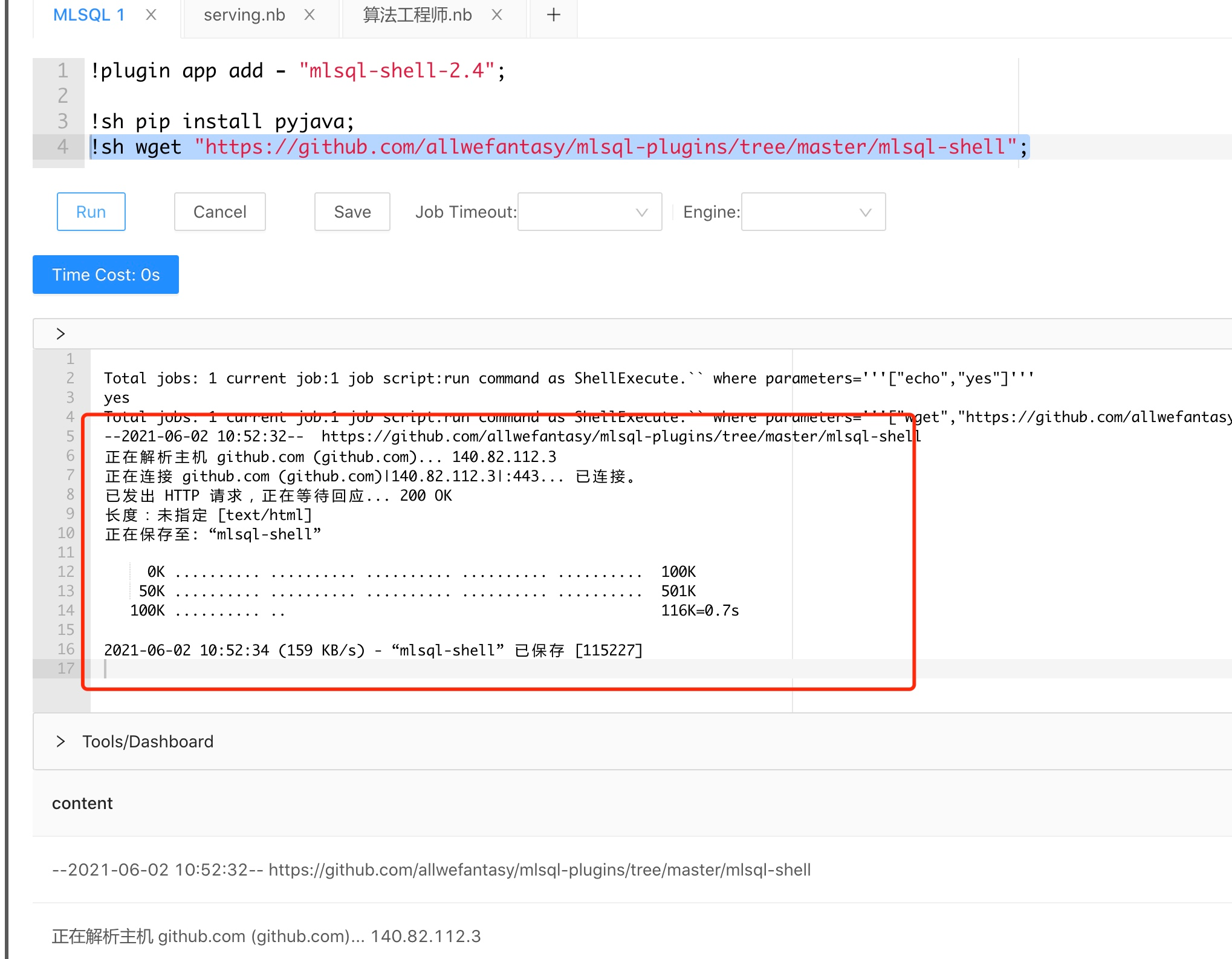
如何安装
在 Web 控制台中执行以下命令:
!plugin app add - "mlsql-shell-2.4";注意:示例中 byzer 的 spark 版本为 2.4 ,如果需要在 spark 3.X 的版本运行,请将安装的插件设置为
mlsql-shell-3.0
执行一个测试脚本,验证是否正确安装:
!sh echo "yes";如何使用
!sh pip install pyjava;
!sh echo "yes";
!sh wget "https://github.com/byzer-org/byzer-extension/tree/master/mlsql-shell";
保存到增量表中再次加载
save then load 插件会将表保存到增量表中,并再次加载。
如何安装
在 Web 控制台中执行以下命令:
!plugin et add - "save-then-load-2.4" named saveThenLoad;注意:示例中 byzer 的 spark 版本为 2.4 ,如果需要在 spark 3.X 的版本运行,请将安装的插件设置为
save-then-load-3.0
如何使用
!saveThenLoad tableName;
select * from tableName as output;
byzer-execute-sql JDBC 插件
JDBC 插件是一个基于JDBC的插件,可以通过JDBC连接各种传统关系型数据库比如 Oracle/DB2/MySQL等,也可以 支持大数据体系下的MPP数据库,执行SQL语句,把数据转化为Byzer内存表。
用户需要确保对应的驱动已经安装到了 Byzer 的 plugin 或者 lib 目录下。
插件信息
- 插件: https://download.byzer.org/byzer-extensions/nightly-build/byzer-execute-sql-3.3_2.12-0.1.0-SNAPSHOT.jar
- 插件入口类:tech.mlsql.plugins.execsql.ExecSQLApp
- 插件名称: byzer-execute-sql-3.3
可以参考在线/离线安装文档进行安装。
使用方式
下面是基本使用方式:
创建一个MySQL 数据库连接:
!conn business
"url=jdbc:mysql://127.0.0.1:3306/business?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&useSSL=false"
"driver=com.mysql.jdbc.Driver"
"user=root"
"password=xxxx";第一个参数是数据库连接名称,后面的参数都是连接必须的配置选项。
断开一个 MySQL 数据库链接:
!conn remove business;在 MySQL中执行诸如创建临时表等操作(这里)
!exec_sql '''
create table1 from select content as instruction,"" as input,summary as output
from tunningData
''' by business;指定连接执行SQL,主要是一些创建MPP虚拟表的操作。如果没有异常,不会有返回。
把 MySQL 的数据转化为 Byzer 内存表 tunningData 使用:
!exec_sql tunningData from '''
select content as instruction,"" as input,summary as output
from tunningData
''' by business;
select * from tunningData as output;注意,这里是内存表,数据都会保存在内存里。所以数据规模不能太大,最好加上limit限制。

无需安装部署,在线快速体验 Byzer
更多推荐
 0
0 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)