
插件开发
自定义 ET 插件开发 ET 概念 Byzer具备足够灵活的扩展性,能够同时解决 Data + AI 领域的问题。我们提供了大量的插件,方便用户在数据处理、商业分析和机器学习的不同场景中使用 Byzer。这些插件类型包括: DataSource、ET、Script、App,我们都可以灵活的通过离线或者线上的方式注册到 Byzer Engine 中使
自定义 ET 插件开发
ET 概念
Byzer具备足够灵活的扩展性,能够同时解决 Data + AI 领域的问题。我们提供了大量的插件,方便用户在数据处理、商业分析和机器学习的不同场景中使用 Byzer。这些插件类型包括: DataSource、ET、Script、App,我们都可以灵活的通过离线或者线上的方式注册到 Byzer Engine 中使用。
在 Byzer 中,ET(Estimator/Transformer 的简称)是一个非常重要的概念。通过 ET,我们可以完成非常多的复杂任务。包括:
- 无法用 SQL 实现的特定的数据处理
- 实现各种可复用的复杂的算法模型以及特征工程工具
- 提供各种便利工具,比如发送邮件、生成图片等各种必需的工具
ET 也是实现将算法的特征工程从训练复用到预测时的核心,即大部分特征工程训练完成后都可以转化为一个函数,从而供给预测时使用。比如 train,register,predict 语法去抽象机器学习流程,通过 ET 一站式解决模型的训练、注册、预测的语法定制。本节,我们会以表抽取插件为例,来介绍如何用包装 Spark 内置的工具应用 于 Byzer 中。
查看系统可用 ET
可使用功能如下命令查看所有可用的 ET:
!show et;模糊匹配查询 ET
需要模糊匹配某个 ET 的名字,可以使用如下方式:
!show et;
!lastCommand named ets;
select * from ets where name like "%Random%" as output;同理,你也可以实现根据关键字模糊检索 doc 字段。
查看 ET 代码示例和使用文档
通过上面的方式,知道 ET 具体名字后,你可以查看该 ET 的使用示例等信息:
!show et/RandomForest;查看 ET 可选参数
此外,如果你想看到非常详尽的参数信息,可以通过如下命令:
!show et/params/RandomForest;为了方便灵活地开发 ET 插件,用户可以根据插件的类型,选择插件接入到哪个位置,我们提供了三种接入方式:
- 直接修改 Byzer 源码
- 独立成模块作为内置插件使用
- 独立成项目作为外置插件使用
下面我们将重点介绍第一种方式——直接修改 Byzer 源码的方式添加 ET 插件。
ET 使用语法
以 ET 插件SyntaxAnalyzeExt为例,其功能是用来解析SQL中的输入、输出表。我们需要使用 run 语法对数据进行处理,其中语法解析的类型 action 为 extractTables,表示抽取表名,sql为待解析的sql语句,如下:
run command as SyntaxAnalyzeExt.`` where
action="extractTables" and sql='''
select a from table1 as output;
''';下面给一个完整的例子。首先生成两个表,table1 和 table2。然后执行SyntaxAnalyzeExt抽取一个嵌套 SQL 的所有的表。 如下:
select "stub" as table1;
select "stub" as table2;
run command as SyntaxAnalyzeExt.`` where
action = "extractTables" and sql='''
select * from (select * from table1 as c) as d left join table2 as e on d.id=e.id
''' as extractedTables;
select * from extractedTables as output;在 Byzer notebook 中,可以看到结果如下:
| tableName |
|---|
| table1 |
| table2 |
ET 开发
要实现一个 ET 的开发,需要实现如下接口:
- SQLAlg 定义 ET 的 train/batchPredict/load/predict 函数
- WowParams 定义函数,并添加 Param 函数说明和 Doc 文档说明
- ETAuth 权限控制
- VersionCompatibility 版本兼容
最后,将开发好的 ET 注册到 ETRegister 中,启动我们的 Byzer Engine 即可使用了。下面我们来一起看一下如何实现一个 ET,用于抽取 SQL 语句中所有的表名功能。
Class definition
首先,介绍一个目前 Byzer 里已经提供了一个工具类,可以让我们复用 Spark SQL 解析器来进行解析抽取表名:
object MLSQLAuthParser {
val parser = new AtomicReference[WowSparkSqlParser]()
def filterTables(sql: String, session: SparkSession) = {
val t = ArrayBuffer[WowTableIdentifier]()
lazy val parserInstance = new WowSparkSqlParser(session.sqlContext.conf)
parser.compareAndSet(null, parserInstance)
parser.get().tables(sql, t)
t
}
}我们发现 MLSQLAuthParser 用法也比较简单,只要在 SyntaxAnalyzeExt 调用该类即可。
接下来,新建一个类SyntaxAnalyzeExt,需要注意所有的ET都需要继承 *streaming.dsl.mmlib.SQLAlg*
class SyntaxAnalyzeExt extends SQLAlg {然后你需要实现 SQLAlg 的所有方法。核心方法是四个:
def train(df: DataFrame, path: String, params: Map[String, String]): DataFrame
def load(sparkSession: SparkSession, path: String, params: Map[String, String]): Any
def predict(sparkSession: SparkSession, _model: Any, name: String, params: Map[String, String]): UserDefinedFunction
def batchPredict(df: DataFrame, path: String, params: Map[String, String]): DataFrame = {
val sparkSession = df.sparkSession
import sparkSession.implicits._
Seq.empty[(String, String)].toDF("param", "description")
}- train 对应 train 和 run 语法关键字。注意 run/train 具有完全一致的用法,但是目的不同。 run 的语义是对数据进行处理,而不是训练,他是符合大数据处理的语义的,在我们这个例子中是用于 run 语法。
- batchPredict 对应 predict 语法关键字,为了批量预测用的。
- load 对应 load 语法关键字,用于加载目录下的数据。
- predict 则对应 register 语法关键字。 将模型注册成UDF函数,方便在批/流/API中使用。
Override train
我们看到,train 其实接受了很多参数。这些参数都是 train 里的 params 传递的。我们看到 params 的签名是 Map[String, String] , 所以在 Byzer 中,所有的属性配置都是字符串。我们先对方法做个解释:
def train(
df: DataFrame, //需要处理的数据
path: String, //处理后需要保存的路径
params: Map[String, String]): //所有配置参数
DataFrame //返回结果一般是显示处理的结果,比如时间,是否成功等等。从这个函数签名,对应下之前的SQL:
run command as SyntaxAnalyzeExt.`` where action="extractTables" and sql=''' ... ''';是不是非常清晰了?我们再看下需要实现的接口:
class SyntaxAnalyzeExt(override val uid: String) extends SQLAlg
with WowParams // 用于让你暴露出你需要的配置参数。也就是train/run语法里的where条件。
with Logging with WowLog // 用于打印日志
with ETAuth // 用于ET权限控制
with VersionCompatibility // 兼容哪些版本的Byzer我们可以使用 Byzer 已经支持的解析器 MLSQLAuthParser ,下面是 train 部分所有的代码:
override def train(df: DataFrame, path: String, params: Map[String, String]): DataFrame = {
val context = ScriptSQLExec.contextGetOrForTest()
// params是一个Map,包含了所有where条件的参数
params.get(sql.name)
// 过滤空白字符和分号结束符
.map(s => s.trim)
.map(s => if (s != "" && s.last.equals(';')) s.dropRight(1) else s)
.filter(_ != "")
.map { s =>
/**
* params.getOrElse(action.name, x)表示获取不到则获取默认值
* getOrDefault(action) 为我们提前在Param中设置好的默认值,我们将在后面代码呈现
*/
params.getOrElse(action.name, getOrDefault(action)) match {
case "extractTables" =>
import df.sparkSession.implicits._
// 输出抽取表结果
MLSQLAuthParser.filterTables(s, context.execListener.sparkSession).map(_.table).toDF("tableName")
}
}.getOrElse {
// 输出空结果
df.sparkSession.emptyDataFrame
}
}这样我们的 train 方法就已经开发好了。
ET 参数定义和一些需要重写的函数
上面说到我们可以定义 where 里面的参数定义、参数默认值等信息,具体如下:
final val action: Param[String] = new Param[String] (this, "action",
// 前端控件类型
FormParams.toJson(Select(
// 参数名
name = "action",
// 值列表
values = List(),
// 附加信息
extra = Extra(
// 使用文档
doc =
"""
| Action for syntax analysis
| Optional parameter: extractTables
| Notice: Currently, the only supported action is `extractTables`,
| and other parameters of the action are under construction.
| e.g. action = "extractTables"
""",
// 标题
label = "action for syntax analysis",
options = Map(
// 值类型
"valueType" -> "string",
// 默认值
"defaultValue" -> "",
// 是否必填
"required" -> "false",
// 依赖类型
"derivedType" -> "NONE"
)), valueProvider = Option(() => {
// 枚举值列表
List(KV(Option("action"), Option("extractTables")))
})
)
)
)
// 设置spark params默认值
setDefault(action, "extractTables")
// 把所有模型参数罗列。我们可以方便的在sql中使用modelParams来查看参数介绍。
override def explainParams(sparkSession: SparkSession): DataFrame = {
_explainParams(sparkSession)
}
// 标识是数据预处理还是算法,默认未定义。常用的三种是:algType、processType、undefinedType。
override def modelType: ModelType = ProcessType
// 是否自动补充主目录,大部分都需要。所以保持默认即可。
override def skipPathPrefix: Boolean = false
// 指定该插件能够兼容哪些版本的Byzer。Byzer会在加载插件的时候会通过该检查兼容性。[插件兼容性版本](https://github.com/allwefantasy/mlsql/issues/1544)支持指定版本和指定范围2中方式,如下版本表达式 [2.0.0,) 表示大于或等于 2.0.0
override def supportedVersions: Seq[String] = Seq("[2.0.0,)")我们强烈建议覆盖一下上述函数,方便 ET 的使用方快速了解它。比如,用户可以运行如下 SQL 进行查看:
load modelParams.`SyntaxAnalyzeExt` as output;
-- 2.2.0 版本提供如下方式查看
-- !show et/params/SyntaxAnalyzeExt;执行结果如下:
paramdescriptionactionRequired. action for syntax analysis Optional parameter: extractTables Notice: Currently, the only supported action is extractTables, and other parameters of the action are under construction. e.g. action = "extractTables" (default: extractTables)sqlRequired. SQL to be analyzed e.g. sql = "select * from table" (default: )
在上面的示例中,参数的定义还是比较复杂的,我们也非常建议完成的定义该数据结构,因为在代码自动补全、workflow中插件可视化、了解参数原信息和参数间依赖关系等方面都非常有用。如需了解更多参数机制,请访问开发插件自省参数
ET组件的权限
Byzer 将一切资源都抽象成了表,最细粒度可以控制到列级别。
在 Byzer 中有非常完善的权限体系,我们可以轻松控制任何数据源到列级别的访问权限,而且创新性的提出了编译时权限,也就是通过静态分析 Byzer 脚本从而完成表级别权限的校验(列级别依然需要运行时完成)。
Byzer 的权限内置于语言级别。这意味着,通过 Byzer 我们就可以控制各种数据源的访问,亦或是Byzer 自身的各种功能,我们会在后面的内容具体阐述如何开发Byzer的权限体系。下面用一个图更好的描述:
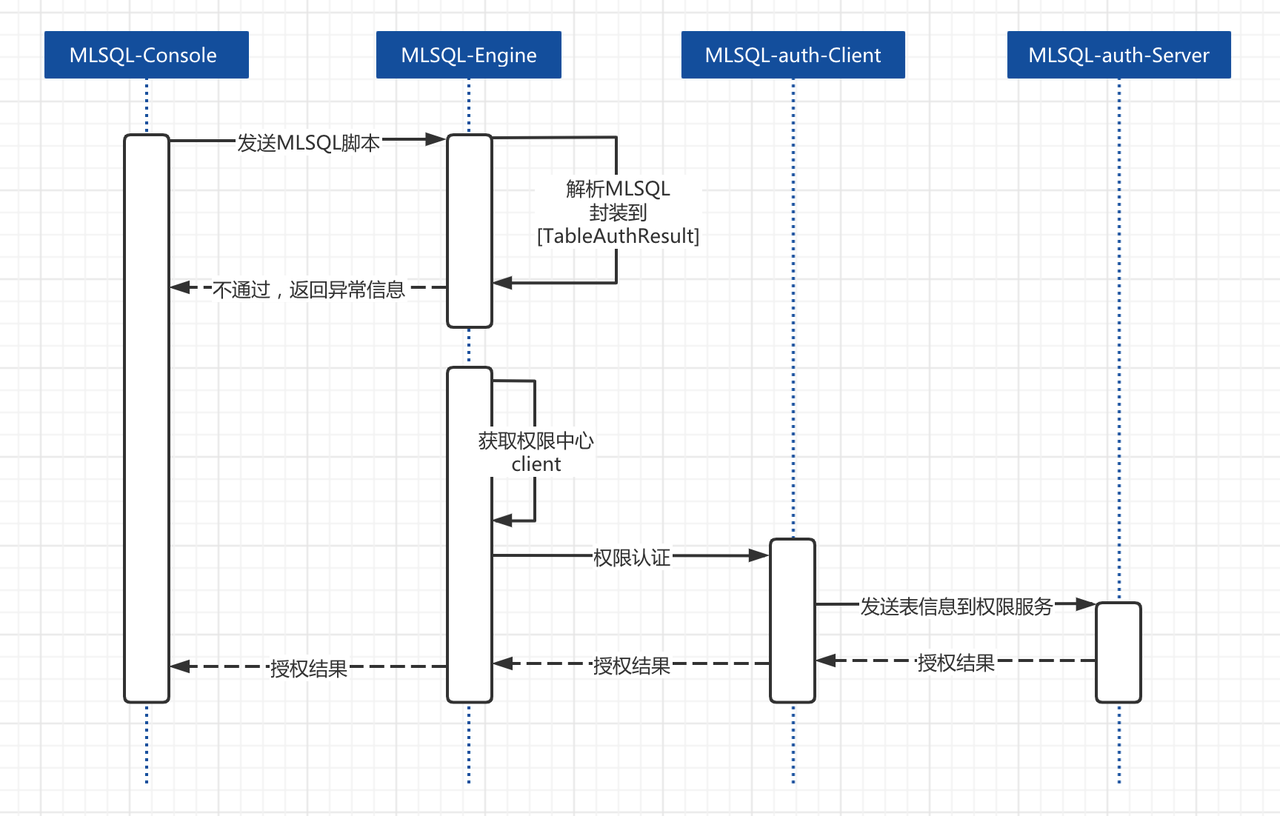
基本描述如下:
- Byzer Engine接收脚本,检查是否开启授权验证
- 如果开启,则解析该脚本所有表,然后获取表相关信息如数据源类型,表名,操作类型 (create/save等)
注意:权限系统只识别库表形态的格式,我们可以把任何东西,抽象成库表的模样,他可以是文件,可以是一个ET,也可以是任意东西。如果我们的输入是空,或者是一个load等语句加载的临时表,不需要对输入表鉴权,因为我们在前面load的操作已经内置了读取路径的权限控制。而这里我们需要控制的是ET插件的使用权限,比如在我们实现的中
SyntaxAnalyzeExt示例表示: 我对库MLSQL_SYSTEM 下的表 syntax_analyze_operator 检查select权限。
- 检查用户配置的client实现,调用其代码,默认的client为
streaming.dsl.auth.client.DefaultConsoleClient - 用户client需要连接自己的授权中心,查看执行脚本的用户是否对这些表有相应的权限,返回权限验证结果。
- 失败,则 Byzer Engine 会拒绝执行该脚本。
- 成功,则 Byzer Engine 会继续执行该脚本。
我们看一下如何在插件中添加一个语法解析的权限控制:
override def auth(etMethod: ETMethod, path: String, params: Map[String, String]): List[TableAuthResult] = {
val vtable = params.getOrElse(action.name, getOrDefault(action)) match {
// 我们在extractTables条件上添加一个权限的定义
case "extractTables" =>
MLSQLTable(
Option(DB_DEFAULT.MLSQL_SYSTEM.toString),
Option("__syntax_analyze_operator__"),
OperateType.SELECT,
Option("select"),
TableType.SYSTEM)
case _ =>
throw new NoSuchElementException("Failed to execute SyntaxAnalyzeExt, unsupported action")
}在auth的实现中,我们发现在条件 extractTables 中定义了一个 MLSQLTable ,表示Byzer解析脚本后返回的表的所有信息,其对应的数据结构如下:
MLSQLTable(
db: Option[String],
table: Option[String],
columns: Option[Set[String]],
operateType: OperateType,
sourceType: Option[String],
tableType: TableTypeMeta)其中对应的字段名称为:
- db: 数据库名称(es、solr是index名称、hbase为namespace名称)
- table: 表名称(es、solr是type名称、mongo为集合、hdfs为全路径)
- operateType: create、drop、load、save、select、insert
- sourceType: hbase、es、solr、mongo、jdbc(mysql、postgresql)、hdfs(parquet、json、csv、image、text、xml)
- tableType: table的元数据类型
对应到我们的SyntaxAnalyzeExt表示如下含义:
- db(数据库名称): DB_DEFAULT.MLSQL_SYSTEM
- table(表名):syntax_analyze_operator
- operateType(操作类型):OperateType.SELECT
- sourceType(源类型):select
- tableType(表类型):TableType.SYSTEM
实际上我们SQL语句在解析的时候,会检测我们用户是否配置跳过权限验证,没有配置跳过则会调用我们实现的 auth 函数生成 *List[MLSQLTable]* ,我们可以看下 ScriptSQLExec.parse对权限的处理,如下面源码所示:
// 获取auth_client
val authImpl = staticAuthImpl match {
case Some(temp) => temp
case None => context.userDefinedParam.getOrElse("__auth_client__",
Dispatcher.contextParams("").getOrDefault("context.__auth_client__", "streaming.dsl.auth.client.DefaultConsoleClient").toString)
}
// 执行auth_client中的auth函数
val tableAuth = Class.forName(authImpl)
.newInstance().asInstanceOf[TableAuth]
sqel.setTableAuth(tableAuth)
tableAuth.auth(authListener.tables().tables.toList)系统通过参数将 *List[MLSQLTable]* 传递给你。接着你就可以将这些信息转化为用户已有【权限系统】可以识别的格式发给用户。用户启动的时候,需要配置:
--conf spark.mlsql.auth.implClass streaming.dsl.auth.client.MLSQLConsoleClient或者,在请求参数里 context.__auth_client__ 带上全路径。在我们的 auth_client 中可以看到,我们通过 http 请求到实际的 auth_server,完成一次权限的认证,如下源码所示:
// 获取配置中的__auth_server_url__
val authUrl = context.userDefinedParam("__auth_server_url__")
// 获取配置中的__auth_secret__
val auth_secret = context.userDefinedParam("__auth_secret__")
try {
// 请求到权限服务
val returnJson = Request.Post(authUrl).
bodyForm(Form.form().add("tables", jsonTables).
add("owner", owner).add("home", context.home).add("auth_secret", auth_secret)
.build(), Charset.forName("utf8"))
.execute().returnContent().asString()在权限服务中会对请求中的进行验证,我们看下通过内置的MLSQLConsoleClient请求到对应的权限服务, TableAuthController 处理逻辑:
// 现在我们将检查所有表的身份验证
val finalResult = tables.map { t =>
(getOrUndefined(t.db) + "_" + getOrUndefined(t.table) + "_" + t.tableType.name + "_" + getOrUndefined(t.sourceType) + "_" + t.operateType.toString, t)
}.map { t =>
// 通过checkAuth判断MLSQLTable的权限
checkAuth(t._1, t._2, home, authTables)
}
...
def checkAuth(key: String, t: MLSQLTable, home: String, authTables: Map[String, String]): Boolean = {
// 是否为非法的operateType
if (forbidden(t, home)) return false
// 判断没有权限的场景
if (withoutAuthSituation(t, home)) return true
return authTables.get(key) match {
case Some(_) => true
case None => false
}
}
...
// 返回认证结果
render(200, JSONTool.toJsonStr(finalResult))从上面的例子可以看出,用户需要实现 TableAuth 接口以及里面的auth方法,系统通过参数将前面我们描述的 List[MLSQLTable] 传递给你。接着你就可以将这些信息转化为用户已有【权限服务】可以识别的格式发给用户。
如果想测试一下我们插件的Auth认证,首先,要设置Console不跳过权限认证。
然后我们在Byzer Engine启动项配置好请求权限服务的AuthClient客户端,这里演示Byzer内置的client:
"-spark.mlsql.auth.implClass", "streaming.dsl.auth.client.MLSQLConsoleClient"MLSQLConsoleClient会在auth函数中请求到我们Console中内置的权限服务,完成权限校验。我们也可以通过简单的Client实现,不请求Server查看效果,配置如下:
"-spark.mlsql.auth.implClass", "streaming.dsl.auth.client.DefaultConsoleClient"在Byzer中也支持列级别的控制,如果需要了解更多Byzer权限相关的内容,参考:编译时权限控制
注册到Byzer引擎
到目前为止,我们就实现了一个抽取表名称的 ET 插件了。那么如何注册到 Byzer 引擎中呢?如果是作为内置插件,我们只要添加如下一行代码到tech.mlsql.ets.register.ETRegister即可:
register("SyntaxAnalyzeExt", "tech.mlsql.plugins.ets.SyntaxAnalyzeExt")如果是一个外部插件,我们可以通过网络安装的方式或者离线安装方式,以 jar 的方式添加到 Byzer 引擎中,具体实现方法在本文下面的小节 作为外置插件使用 会有介绍。
现在,你启动 IDE,就可以使用这个模块了。
我们开发好的 ET 可以很简单的封装为宏命令,简化交互上的使用。比如 ET SQLShowTableExt,就是我们常用的命令 !desc,我们可以参考文章: 命令行开发
我们来复习一下实现一个 ET 的核心要素和规范:
- 继承 SQLAlg ,根据ET的功能我们实现SQLAlg的方法 train/batchPredict/load/predict,并实现ModelType
- 实现 WowParams,添加参数 Param 定义和文档 Doc、codeExample 定义
- 实现 VersionCompatibility 接口,实现方法 supportedVersions
- 实现 ETAuth接口,并实现方法 auth
1,2,4必须实现,3可选。
另一个模型ET的示例
我们已经知道如何实现一个 run 语法的 ET,并投入使用,那么如果是一个算法插件,除了 train 外,其他的几个函数的功能我们应该怎么实现呢?
我们以RandomForest为例,看下一个模型怎么在Byzer中使用。
set jsonStr='''
{"features":[5.1,3.5,1.4,0.2],"label":0.0},
{"features":[5.1,3.5,1.4,0.2],"label":1.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[4.4,2.9,1.4,0.2],"label":0.0}
''';
load jsonStr.`jsonStr` as data;
select vec_dense(features) as features,label as label from data
as data1;
-- 使用RandomForest的train语法进行训练
train data1 as RandomForest.`/tmp/model` where
-- 一旦设置为 true,每次运行此脚本时,Byzer 都会为您的模型生成新目录
keepVersion="true"
-- 指定测试数据集
and evaluateTable="data1"
-- 指定第0组参数
and `fitParam.0.labelCol`="features"
and `fitParam.0.featuresCol`="label"
and `fitParam.0.maxDepth`="2"
-- 指定第1组参数
and `fitParam.1.featuresCol`="features"
and `fitParam.1.labelCol`="label"
and `fitParam.1.maxDepth`="10"
;
-- 注册为函数rf_predict
register RandomForest.`/tmp/model` as rf_predict;
-- 使用函数进行预测
select rf_predict(features) as predict_label from trainData
as output;我们通过走读下面的代码,来看下 RandomForest 模型 ET 是如何实现的。
// 因为我们使用了Spark MLLib里的params,所以需要override uid。
class SQLRandomForest(override val uid: String) extends SQLAlg
with MllibFunctions // spark mllib相关辅助函数。
with Functions // 辅助函数
with BaseClassification // 参数比如 keepVersion, fitParam等等 下面是 train 函数:
// 获取keepVersion的值
val keepVersion = params.getOrElse("keepVersion", "true").toBoolean
setKeepVersion(keepVersion)
val evaluateTable = params.get("evaluateTable")
setEvaluateTable(evaluateTable.getOrElse("None"))
// 递增版本
SQLPythonFunc.incrementVersion(path, keepVersion)
val spark = df.sparkSession
// 多组参数解析,包装Mllib里的算法,最后进行训练,并且计算效果
trainModelsWithMultiParamGroup[RandomForestClassificationModel](df, path, params, () => {
new RandomForestClassifier()
}, (_model, fitParam) => {
evaluateTable match {
case Some(etable) =>
val model = _model.asInstanceOf[RandomForestClassificationModel]
val evaluateTableDF = spark.table(etable)
val predictions = model.transform(evaluateTableDF)
multiclassClassificationEvaluate(predictions, (evaluator) => {
evaluator.setLabelCol(fitParam.getOrElse("labelCol", "label"))
evaluator.setPredictionCol("prediction")
})
case None => List()
}
}
)
// 输出训练结果
formatOutput(getModelMetaData(spark, path))一旦模型训练完成之后,我们会把训练参数,模型等都保存起来。之后我们需要加载这些信息,用于预测时使用。下面是 load 函数:
override def load(sparkSession: SparkSession, path: String, params: Map[String, String]): Any = {
/*
可以加载任意spark内置模型,返回多个模型路径,元数据路径等。我们一般取第一个(已经根据evaluateTable进行了打分,打分
最高的排在最前面),最后加载成模型
*/
val (bestModelPath, baseModelPath, metaPath) = mllibModelAndMetaPath(path, params, sparkSession)
val model = RandomForestClassificationModel.load(bestModelPath(0))
ArrayBuffer(model)
}批量预测本质是调用 load 得到模型,然后调用 spark 内置的 transform方法:
override def batchPredict(df: DataFrame, path: String, params: Map[String, String]): DataFrame = {
val model = load(df.sparkSession, path, params).asInstanceOf[ArrayBuffer[RandomForestClassificationModel]].head
model.transform(df)
}将模型注册为UDF函数:
override def predict(sparkSession: SparkSession, _model: Any, name: String, params: Map[String, String]): UserDefinedFunction = {
predict_classification(sparkSession, _model, name)
}这样我们就定义好了一个模型的 load、train、predict、register 过程,我们可以很方便的包装任何 Spark 的内置算法作为 ET 使用。
独立成模块作为内置插件使用
上面我们介绍了直接修改 Byzer 源码的方式添加 ET,如果你希望这个插件是一个独立的模块,并且内置在 Byzer 中,那么你需要在 external 目录下新建一个模块,然后在tech.mlsql.runtime.PluginHook 添加该内置插件。另外,你还需要在 streamingpro-mlsql 添加该该模块依赖。通常添加在profile/streamingpro-spark-2.4.0-adaptor 和 profile/streamingpro-spark-3.0.0-adaptor 中都要添加。如果你这个模块只兼容其中一个,添加一个即可。
作为外置插件使用
如果你想作为外置插件使用,也就是单独做成一个项目开发和维护,可以参考项目: byzer-extension
模式和内置插件一样,然后打成jar包,使用离线安装的方式安装,即手动下载好jar包放置到程序目录,并在启动命令中设置 jar 包以及启动类。MLSQL 外置插件可以动态安装,但是如果要更新,则需要重启服务。
我们也支持网络安装插件,直接使用命令行方式在 Console 里安装。比如,如果需要安装 excel 支持,一行命令在 MLSQL Console 里即可搞定:
!plugin ds add - "mlsql-excel-3.0";自定义数据源插件开发
数据源主要应用于 byzer 的 Load/Save 语法里。尽管 byzer 提供了非常多的数据源支持加载和存储多种数据源,但肯定还有非常的数据源并没有被官方支持到。byzer 为此提供了自定义数据源的支持。
通常,为了达成此目标,用户大体需要实现两个步骤:
- 按 Spark DataSource 标准封装对应的数据源。因为 Spark 良好的生态储备,一般而言大部分数据源都会有 Spark 的Connector(DataSource)。 所以这一步实际上仅仅是引入相应的 Connector Jar 包即可。
- 按 byzer DataSource 标准进一步封装 Spark DataSource 数据源(或者原生的数据源)。比如我们常用的jsonStr,csvStr 等就没有使用 Spark DataSource Connector,而是职级使用 byzer DataSource 标准实现的。
在这篇教程中,我们不会介绍 Spark DataSource 的开发,而是介绍 byzer DataSource 的标准。
byzer Excel 数据源介绍
加载或者保存 Excel 会是一个较为常见的操作,我们在byzer-extension实现了 excel 在 byzer 中的读取和保存。
使用如下:
load excel.`/tmp/upload/example_en.xlsx`
where useHeader="true" and
maxRowsInMemory="100"
and dataAddress="A1:C8"
as data;保存如下:
select 1 as as as b;
save overwrite b as excel.`/tmp/b.xlsx` where header="true"; |现在我们来看看如何进行开发。
Excel 数据源开发
要实现一个数据源的开发,需要实现如下接口:
- MLSQLSource 读取操作
- MLSQLSink 写入操作
- MLSQLSourceInfo 权限校验信息的生成
- MLSQLRegistry 注册数据源名称
- VersionCompatibility 版本兼容
1,2 必须实现其中一个,3 可选,4 必须。
MLSQLSource 的签名:
trait MLSQLSource extends MLSQLDataSource with MLSQLSourceInfo {
def load(reader: DataFrameReader, config: DataSourceConfig): DataFrame
}MLSQLSink 的签名:
trait MLSQLSink extends MLSQLDataSource {
def save(writer: DataFrameWriter[Row], config: DataSinkConfig): Any
}MLSQLSourceInfo的签名:
trait MLSQLSourceInfo extends MLSQLDataSource {
def sourceInfo(config: DataAuthConfig): SourceInfo
def explainParams(spark: SparkSession): DataFrame = {
import spark.implicits._
spark.createDataset[String](Seq()).toDF("name")
}
}不过通常都会有一些基类,简化我们的操作。比如如果你实现的是文件类操作,那么就可以选用streaming.core.datasource.MLSQLBaseFileSource作为实现的基类。MLSQLExcel 也会选择该类作为基类。
下面是签名:
class MLSQLExcel(override val uid: String)
extends MLSQLBaseFileSource
with WowParams with VersionCompatibility {
def this() = this(BaseParams.randomUID())我们先来看看如何 Register 我们的数据源:
override def register(): Unit = {
DataSourceRegistry.register(MLSQLDataSourceKey(fullFormat, MLSQLSparkDataSourceType), this)
DataSourceRegistry.register(MLSQLDataSourceKey(shortFormat, MLSQLSparkDataSourceType), this)
}
override def fullFormat: String = "com.crealytics.spark.excel"
override def shortFormat: String = "excel"定义 fullFormat,shortFormat。 fullFormat 是 Spark 数据源的类型。shortFormat 则是你给这个数据源取的短名。这样我们可以在 load/save 语句中直接使用 excel。
register 方法会将相关信息注册到一个统一的地方。
接着是提供权限校验的一些必要信息:
override def sourceInfo(config: DataAuthConfig): SourceInfo = {
val context = ScriptSQLExec.contextGetOrForTest()
val owner = config.config.get("owner").getOrElse(context.owner)
SourceInfo(shortFormat, "", resourceRealPath(context.execListener, Option(owner), config.path))
}其实就是要拼装出一个 SourceInfo 对象,这个对象会交给校验服务器进行校验。
最后是版本兼容,你需要明确指定兼容哪些版本的 byzer。
override def supportedVersions: Seq[String] = {
Seq("1.5.0-SNAPSHOT", "1.5.0", "1.6.0-SNAPSHOT", "1.6.0", "2.0.0", "2.0.1", "2.0.1-SNAPSHOT","2.1.0-SNAPSHOT",
"2.1.0")
}在 byzer Excel 这个示例中,load/save 完全交给基类就好了。如果有特殊需求,可由覆盖基类。我们来看看基类是如何实现数据加载的。具体代码如下:
override def load(reader: DataFrameReader, config: DataSourceConfig): DataFrame = {
val context = ScriptSQLExec.contextGetOrForTest()
val format = config.config.getOrElse("implClass", fullFormat)
val owner = config.config.get("owner").getOrElse(context.owner)
reader.options(rewriteConfig(config.config)).format(format).load(resourceRealPath(context.execListener, Option(owner), config.path))
}通过ScriptSQLExec对象可以获取一个 context 对象,该对象可当前 HTTP 请求的所有请求参数。 config: DataSourceConfig则包含了 load where 条件里的所有参数,对应的是:
useHeader="true" and
maxRowsInMemory="100"
and dataAddress="A1:C8"接着将这些参数设置到 reader 里,并且通过 resourceRealPath 解析到 excel 文件的实际路径,因为我们有主目录的概念。这里是标准的 DataFrame 读 API 了。
相应的,save 操作也是类似的:
override def save(writer: DataFrameWriter[Row], config: DataSinkConfig): Any = {
val context = ScriptSQLExec.contextGetOrForTest()
val format = config.config.getOrElse("implClass", fullFormat)
val partitionByCol = config.config.getOrElse("partitionByCol", "").split(",").filterNot(_.isEmpty)
if (partitionByCol.length > 0) {
writer.partitionBy(partitionByCol: _*)
}
writer.options(rewriteConfig(config.config)).mode(config.mode).format(format).save(resourceRealPath(context.execListener, Option(context.owner), config.path))
}当然了,用户也可以完全实现自己的逻辑,比如读取一个图片什么的,直接使用 HDFS API 去读取即可。可以使用我们封装好的tech.mlsql.common.utils.hdfs.HDFSOperator读取。
这段代码是保存图片例子:
override def save(writer: DataFrameWriter[Row], config: DataSinkConfig): Unit = {
val context = ScriptSQLExec.contextGetOrForTest()
val baseDir = resourceRealPath(context.execListener, Option(context.owner), config.path)
if (HDFSOperator.fileExists(baseDir)) {
if (config.mode == SaveMode.Overwrite) {
HDFSOperator.deleteDir(baseDir)
}
if (config.mode == SaveMode.ErrorIfExists) {
throw new MLSQLException(s"${baseDir} is exists")
}
}
config.config.get(imageColumn.name).map { m =>
set(imageColumn, m)
}.getOrElse {
throw new MLSQLException(s"${imageColumn.name} is required")
}
config.config.get(fileName.name).map { m =>
set(fileName, m)
}.getOrElse {
throw new MLSQLException(s"${fileName.name} is required")
}
val _fileName = $(fileName)
val _imageColumn = $(imageColumn)
val saveImage = (fileName: String, buffer: Array[Byte]) => {
HDFSOperator.saveBytesFile(baseDir, fileName, buffer)
baseDir + "/" + fileName
}
config.df.get.rdd.map(r => saveImage(r.getAs[String](_fileName), r.getAs[Array[Byte]](_imageColumn))).count()
}使用
开发完成后,就可以打包了了。你可以选择 在线或者离线安装。因为是自己开发的,一般都选择离线安装。
命令行开发
在上一篇文章里,我们开发了一个 EmptyTable,正常使用是这样的:
-- table1 就是 train 的第一个参数 df
run table1
as EmptyTable.``
-- where 在 train 方法里可以通过 params 拿到
where ...
-- outputTable 就是 train 的返回值
as outputTable;如果我希望像下面这么使用怎么办?
!emptyTable _ -i table1 -o outputTable;在 EmptyApp 里加上一句话即可:
package tech.mlsql.plugins.ets
import tech.mlsql.dsl.CommandCollection
import tech.mlsql.ets.register.ETRegister
import tech.mlsql.version.VersionCompatibility
/**
* 6/8/2020 WilliamZhu(allwefantasy@gmail.com)
*/
class EmptyTableApp extends tech.mlsql.app.App with VersionCompatibility {
override def run(args: Seq[String]): Unit = {
// 注册 ET 组件
ETRegister.register("EmptyTable", classOf[EmptyTable].getName)
}
// 注册命令,注意,语句最后没有分号
CommandCollection.refreshCommandMapping(Map("saveFile" ->
"""
|run ${i} as EmptyTable.`` as ${o}"
|""".stripMargin))
override def supportedVersions: Seq[String] = Seq("1.5.0-SNAPSHOT", "1.5.0", "1.6.0-SNAPSHOT", "1.6.0")
}
object EmptyTableApp {
}
这个时候,你既可以用 run 语法,也可以用命令行了。MLSQL 还支持比较复杂的脚本化方式。前面的例子是使用命名参数,用户也可以使用占位符:
run {0} as EmptyTable.`` as {-1:next(named,uuid())}"这个时候语法是这样的:
!emptyTable table1 named outputTable;其中{0}表示第一个参数。 {-1}表示不使用占位,而是使用匹配,匹配规则是named字符串后面的值,在这里是outputTable,如果没有则使用 uuid() 函数随机生成一个。
如果不想事先确定用户会填写什么参数,可以这么写:
run command as EmptyTable.`` where parameters='''{:all}"不过需要修改下获取参数的代码,你可以在 EmptyTable 插件中通过如下方式获得一个字符串数组:
val command = JSONTool.parseJson[List[String]](params("parameters"))然后自己匹配命令。
参数自省机制介绍
MLSQL ET 设计时,尽可能实现自省。所谓自省,就是用户可以通过 ET 提供的辅助命令完成对 ET 的一些二次封装。
罗列所有 ET
-- 获取所有ET
!show et;
-- 过滤某个ET
!lastCommand named ets;
select * from ets where name like "%Random%" as output;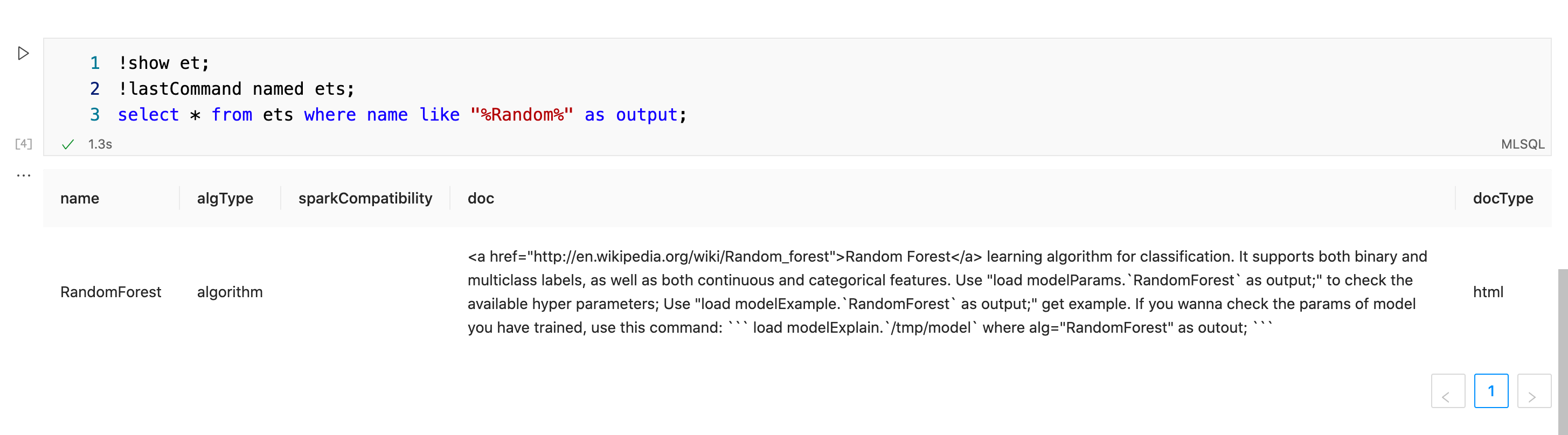
这里DocType会指定了文档的类型,方便前端做渲染(比如是html或者markdown等)。
查看某个ET文档:
!show et/RandomForest;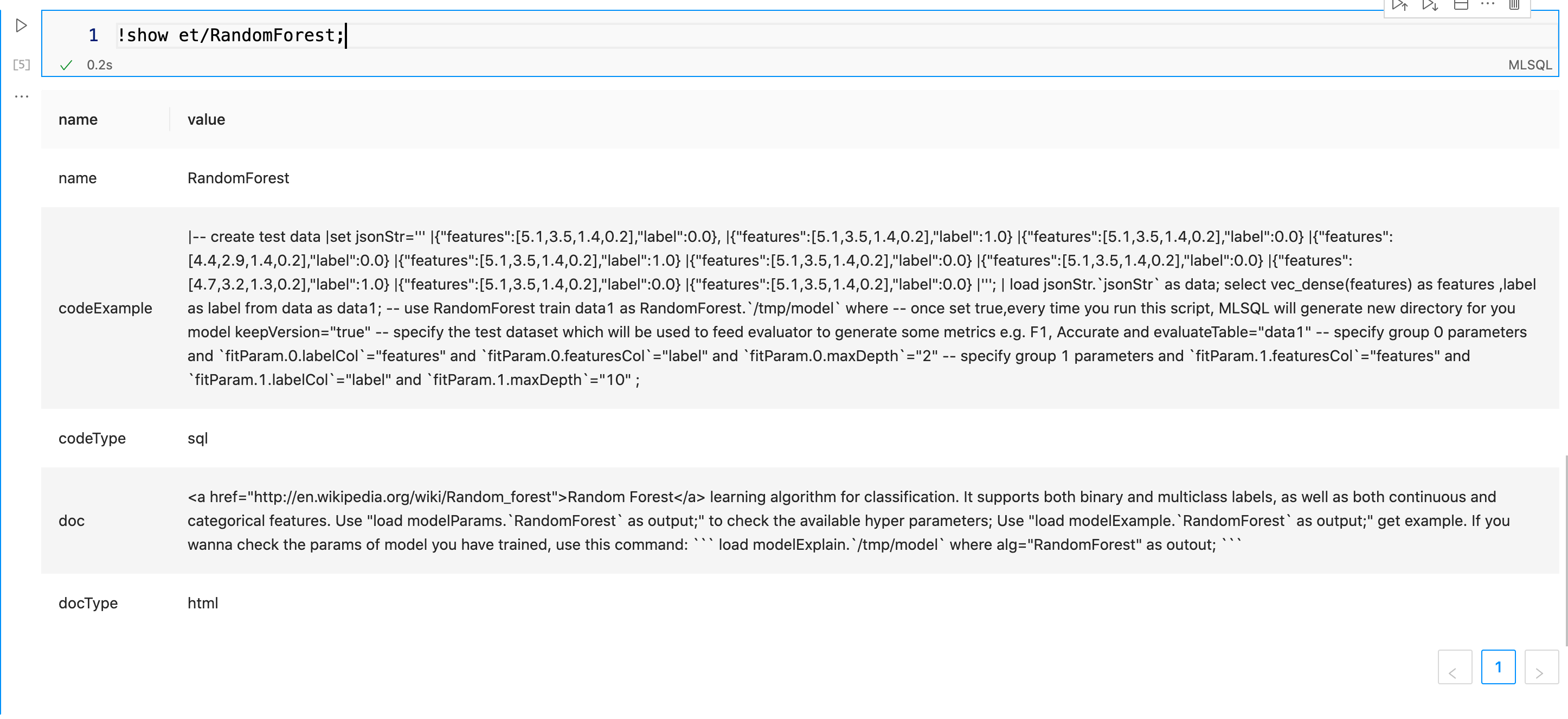
这个命令会显示更多的信息,包括示例文档。 示例中,codeType显示“sql”,表示是标准的MLSQL文本。 doc是html格式的文档。这些信息都可以方便前端做渲染,帮助用户更好的使用该 ET。
显示 ET 的参数
load modelParams.`RandomForest` as output;这里的 param表示参数,description则是对参数的描述。 value则会以字符串的形式把默认值、当前设置的值显示出来。 这些参数是给用户查看的。为了方便程序的二次封装使用,我们在PR,新增了一个extra参数。该extra丰富了参数的描述。接下来我们用上面的例子做一下演示。
keepVersion 参数拥有extra 参数,该参数为Json格式,具体内容如下:
{
"name":"keepVersion", // 参数名
"values":[
{
"name":"keepVersion", // 组件名称
"value":"true" // 枚举值
},
{
"name":"keepVersion", // 组件名称
"value":"false" // 枚举值
}
],
"extra":{ // 附加信息
"doc":"If set true, then every time you run the \" +\n \"algorithm, it will generate a new directory to save the model.", //参数介绍
"label":"", // 参数标题
"options":{ // 扩展内容
"valueType":"string", // 值类型[1]
"derivedType":"NONE", // 伴生类型[2]
"required":"false", // 是否必要,非必要:false,必要:true
"defaultValue":"true", // 默认值,表示keepVersion默认值为true
"currentValue":"undefined" // 当前值,如果没有的话,则为undefined
}
},
"tpe":"Select", // 前端组件类型[3]
"valueProvider":{
}
}参数名称为keepVersion , 基础类型为 Select,也就是一般使用单选框。可选值为 values,可以看到是kv形式的。在 extra中,我们还可以获得更多信息,比如doc是该字段的描述信息, label 是展示给用户看到的字段名称, extra.options 则提供了该参数的默认值以及被新设置的值。如果没有的话,则为undefined。
可以看到,根据这个json字段的信息,前端已经可以获取到足够的信息去渲染该字段了。
另外,我们需要在参数定义中维护一个表示参数依赖的字段,用于展示伴生参数的依赖的参数。我们维护在Dynamic类型的参数中,前端需要发起一次请求,请求通过*set* 语法设置partitonType的值,最后结合*valueProviderName* 生成判断是否是值依赖的代码。具体参考下面第6条。
上述JSON示例中,注释[数字] 位置将在下面介绍。
[1], 值类型可选值如下
| MLSQL值类型(valueType) | 备注 |
|---|---|
| string | 字符串类型 |
| int | 整型类型 |
| float | 单精度浮点数类型 |
| double | 双精度浮点数类型 |
| array[int] | 整型数组类型 |
| array[double] | 浮点数数组类型 |
| boolean | 布尔类型 |
| array[string] | 字符串数组类型 |
| long | 长整型 |
| ENUM | TreeSelect类型 |
[2], 伴生类型
伴生类型 (derivedType),伴生即伴随其他参数产生而产生,伴生参数的显示需要紧随原生参数后面,由于参数的依赖关系有时会非常复杂,我们使用下面几种类型来描述不同的伴生类型数据结构:
-
NONE,非伴生类型
-
VALUE_BIND,值绑定,比如在 load 中选择了 csv format,才会出现的参数
-
NOT_EMPTY_BIND,非空绑定,只有填写了某个参数,才会伴生出现
-
DYNAMIC,动态类型,需要前端请求valueProviderName中的sql
这几种类型的具体使用方式,我们将在下面的【字段存在依赖关系】中详细介绍。
[3], 前端组件类型
现支持的前端组件类型:
| 前端控件类型(tpe) | 备注 | 示例 |
|---|---|---|
| Select | 下拉菜单 | 即枚举类型。e.g. tableRepartition 中partitionType值范围为:["hash", "renge"] 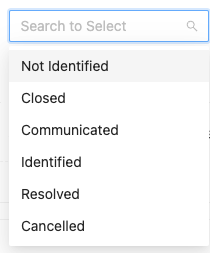 |
| Text | 文本框 | 多行文本。e.g. set rawData=''' {"jack":1,"jack2":2} {"jack":2,"jack2":3} '''; 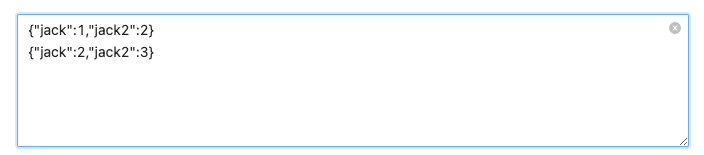 |
| Input | 输入框 | 单行文本。e.g. a="b" |
| CheckBox | 复选框 | 可以选择多个值,且存在值范围。e.g. num="2,3"  |
| Radio | 单选框 | |
| Switch | Switch开关 | 即boolean类型,值范围为:[true,false]  |
| Slider | 滑动轴 | |
| Rate | Rate条 | |
| InputNumber | 数字输入框 | 数字输入框,可以使用上下按钮调整值大小。e.g.  |
| TreeSelect | 树形下拉框 | |
| TimePicker | 时间控件 | |
| Dynamic | 依赖关系绑定 | 依赖关系,用于描述属性的依赖绑定关系。会在下面【ET 参数自省机制开发规范】小节中介绍。 |
| Editor | Editor控件 |
其中,不同的控件类型会有不同的数据结构,下面主要介绍常用的几种控件数据结构。
- Select: 以keepVersion为例,结构如下所示。
{
"name":"keepVersion", // 参数名
"values":[
{
"name":"keepVersion", // 组件名称
"value":"true" // 枚举值
},
{
"name":"keepVersion", // 组件名称
"value":"false" // 枚举值
}
],
"extra":"{ // 附加信息,为jsonString
"doc":"If set true, then every time you run the \" +\n \"algorithm, it will generate a new directory to save the model.", //参数介绍
"label":"", // 参数标题
"options":{ // 扩展内容
"valueType":"string", // 值类型[1]
"derivedType":"NONE", // 伴生类型[2]
"required":"false", // 是否必要,非必要:false,必要:true
"defaultValue":"true", // 默认值,表示keepVersion默认值为true
"currentValue":"undefined" // 当前值,如果没有的话,则为undefined
}
},
"tpe":"Select", // 前端组件类型[3]
"valueProvider":{
}"
}- Text : 以ET TableRepartition为例,结构如下所示(已经注释的字段不再进行注释赘述)。
{
"name":"partitionNum",
"value":"",
"extra": "{
"doc":"\n | Required. Number of repartition.\n | e.g. partitionNum = \"3\"\n ",
"label":"Number of repartition",
"options":{
"valueType":"string", //值类型,可选值:string、boolean、int、long、float、double、array[int]、array[string]、array[boolean]
"derivedType":"NONE",
"required":"true",
"defaultValue":"undefined",
"currentValue":"undefined"
}
},
"tpe":"Text",
"valueProvider":{
}"
}- Input: 示例如下。
{
"name":"inputParam",
"value":"",
"extra": "{
"doc":"",
"label":"inputParam demo",
"options":{
"valueType":"string", //值类型,可选值:string、boolean、int、long、float、double、array[int]、array[string]、array[boolean]
"derivedType":"NONE",
"required":"true",
"defaultValue":"undefined",
"currentValue":"单行文本内容" // 单行文本内容
}
},
"tpe":"Input",
"valueProvider":{
} "
}- CheckBox : 示例如下。
{
"name":"checkBoxParam",
"values": [
{
"name":"group1", // 组件名称
"value":"input01" // 枚举值
},
{
"name":"group1", // 组件名称
"value":"input02" // 枚举值
}
],
"extra": "{
"doc":"",
"label":"inputParam demo",
"options":{
"valueType":"array[string]", // 数组类型,可选值:array[string],array[int], array[double]
"derivedType":"NONE",
"required":"true",
"defaultValue":[""],
"currentValue": [""]
}
},
"tpe":"CheckBox",
"valueProvider":{
} "
}- InputNumber: 示例如下。
{
"name":"InputNumberParam",
"value":"",
"extra": "{
"doc":"",
"label":"InputNumberParam demo",
"options":{
"valueType":"int", // 数值类型,可选值:int、double、long、float
"derivedType":"NONE",
"required":"true",
"defaultValue":"-1",
"currentValue":"1"
}
},
"tpe":"InputNumber",
"valueProvider":{
} "
}- Dynamic:我们支持4种绑定类型(derivedType),分别为:
NONE、STATIC_BIND、DYNAMIC_BIND、GROUP_BIND;
其中NONE 为无绑定;STATIC_BIND 静态绑定会用枚举的方式绑定依赖关系,不需要拼接和查询依赖sql,通过override描述覆盖哪些属性值;DYNAMIC_BIND动态类型需要动态拼接sql,并查询返回依赖关系。
- 下面是STATIC_BIND的示例,以ET TableRepartition为例, 结构如下所示。
{
"name":"shuffle",
"extra": "{
"doc":"\n Whether to start shuffle during the repartition.\n",
"label":"",
"options":{
"valueType":"string", //值类型,可选值:string、boolean、int、long、float、double、array[int]、array[string]、array[boolean]
"derivedType":"STATIC_BIND"
"required":"false",
"defaultValue":"true",
"currentValue":"undefined"
}
} ",
"tpe":"Dynamic",
"subTpe":"Select", // SQL结果类型,可选值:Select->枚举类型,Text->文本类型
"depends":[":partitionType==hash"]
}depends有两种表示方式:
- 字段名称,如:**"depends"**:["partitionType"]。表示shuffle字段依赖partitionType是否有值
- 依赖字段为冒号表达式,如:**"depends":[":partitionType==hash", ":partitionType==range"] 。表示为partitionType 为 hash时shuffle需要显示,默认多个值是或的关系,如果存在复杂规则,需要使用DYNAMIC_BIND进行描述。**
如果是DYNAMIC_BIND(属性多对一依赖或者比较复杂的依赖情况),则使用如下:
{
"name":"partitionCols",
"extra": "{
"doc":"\n Column used for repartition, must be specified when partitionType is range.\n e.g. partitionCols = \"col1\"\n",
"label":"",
"options":{
"valueType":"string", //值类型,可选值:string、boolean、int、long、float、double、array[int]、array[string]、array[boolean]
"derivedType":"DYNAMIC_BIND", //绑定类型:NONE->无绑定, DYNAMIC_BIND->动态绑定,STATIC_BIND->静态绑定
"depends": // 下述属性为与的关系 该参数无绑定关系的uniq_depends, or_depends均为空数组
{},
"required":"false",
"defaultValue":"undefined",
"currentValue":"undefined"
}
},
"tpe":"Dynamic",
"subTpe":"Select", // SQL结果类型,可选值:Select->枚举类型,Text->文本类型
"depends":[ // 依赖的属性,可以为多个。如果存在与或非关系,在valueProviderName中动态描述
"partitionType"
],
"valueProviderName": // 动态查询属性依赖关系的sql,注意:需要前端按照自省机制规则拼接
"\nset partitionType=\"\" where type=\"defaultParam\";\n!if ''' :partitionType == \"hash\" ''';\n!then;\n select true as enabled, false as required as result;\n!else;\n select true as enabled, false as required as result;\n!fi;\nselect * from result as output;\n"
}对于很多算法,我们是wrap的mmlib的实现,里面已经存在很多参数,那么我们该如何将其参数自动转化为上述格式呢?
首先,系统会尝试自动转换,如下图:

可以看到,大部分算法的参数都会被自动转换。尽管如此,比如对于featureSubsetStrategy 他申明的是字符串,但其实是个枚举类型。此时,用户可以通过如下方式覆盖输出:
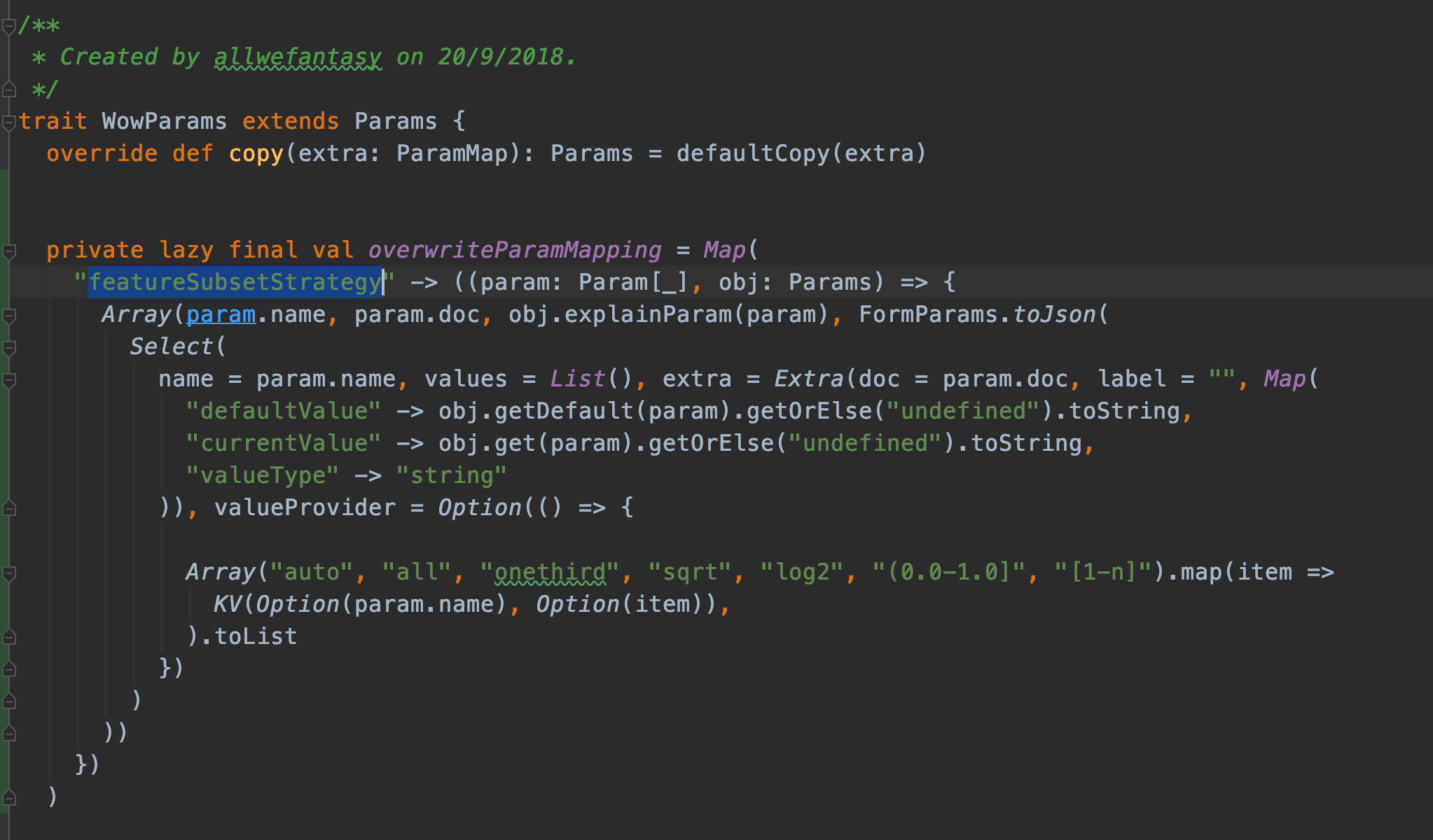
在 WowParams中,添加覆盖参数,从而得到新的渲染结果。这样我们就可以覆盖父类的参数。
现在我们再来看看引擎侧的开发者是如何描述这些信息的,用户只需要在他定义的ET组件中按如下方式定义参数即可:
final val keepVersion: BooleanParam = new BooleanParam(this, "keepVersion",
FormParams.toJson(
Select(
name = "keepVersion",
values = List(),
extra = Extra(
doc = "If set true, then every time you run the \" +\n \"algorithm, it will generate a new directory to save the model.",
label = "",
options = Map()), valueProvider = Option(() => {
List(
KV(Some("keepVersion"), Some("true")),
KV(Some("keepVersion"), Some("false"))
)
})
)
)
)如果参数之间互相有依赖,譬如只有选择了A字段,才能显示B字段,则可以定义一个没有含义的字段,里面使用 Dynamic 来描述已定义字段之间的依赖关系。前端根据Dynamic的信息来控制字段之间的依赖关系。下面是一个简单的示例:
val USER_NAME = Input(UserService.Config.USER_NAME, "")
val NAV_API_ID = Dynamic(
name = "apiNavId",
subTpe = "Select",
depends = List(Params.USER_NAME.name),
valueProviderName = ChooseAPINav.action)值依赖的情况暂时不考虑。
这个表示,这个Dynamic类型也是Select, 字段名称是apiNavId 他依赖参数 userName, 当用户填写了用户名后,前端可以根据URL ChooseAPINav.*action* 获取到这个字段的值列表。
前端如何根据这些信息渲染表单,这里有一个我们实现的参考项目,使用React开发。
字段存在依赖关系
以 TableRepartition 为例,当用户勾选了partitionType字段,并且选择了 *range*值时,此时,用户也必须填写 *partitionCols* 字段。 那么如何描述这种关系呢?这是第一个问题。 第二个问题,假设partitionCols 的是一个Select字段,并且内容需要根据 partitionType的选择值动态变化,这个该如何描述呢?
下面是partitionCols的字段描述:
final val partitionCols: StringArrayParam = new StringArrayParam(this, "partitionCols",
FormParams.toJson(Dynamic(
name = "partitionCols",
extra = Extra(
"""
|
|""".stripMargin, label = "", options = Map(
"valueType" -> "array[string]"
)),
subTpe = "Text",
depends = List("partitionType"),
valueProviderName =
"""
|set partitionType="" where type="defaultParam";
|!if ''' :partitionType == "hash" ''';
|!then;
| select false as enabled as result;
|!else;
| select true as enabled as result;
|!fi;
|select * from result as output;
|""".stripMargin
)
))首先我们申明这是一个动态字段,该字段的行为依赖于partitionType。考虑到用户必须选择了partitionType并且勾选了range才需要触发这个字段。首先,如果用选择了partionType字段,那么就会触发前端发起一次请求,请求需要通过set 语法设置partitonType的值,最后结合valueProviderName 生成如下代码:
-- 前端动态生成的语句
set partitionType="range";
----模板代码
set partitionType="" where type="defaultParam";
!if ''' :partitionType == "hash" ''';
!then;
select false as enabled as result;
!else;
select true as enabled as result;
!fi;
select * from result as output;提交该代码,最后系统会输出 enabled = true(这里可以约定其他格式或者字段名称),也就是说,这个字段需要被启用。结合此时前端根据这个结果,把这个字段动态显示在前端。
如果动态字段在依赖的字段不同的值,对应必填和非必填状态,可以使用如下描述:
final val partitionCols: StringArrayParam = new StringArrayParam(this, "partitionCols",
FormParams.toJson(Dynamic(
name = "partitionCols",
extra = Extra(
"""
|
|""".stripMargin, label = "", options = Map(
"valueType" -> "array[string]"
)),
subTpe = "Text",
depends = List("partitionType"),
valueProviderName =
"""
|set partitionType="" where type="defaultParam";
|!if ''' :partitionType == "hash" ''';
|!then;
| select true as enabled,false as required as result;
|!else;
| select true as enabled,false as required as result;
|!fi;
|select * from result as output;
|""".stripMargin
)
))下面是完整的代码例子:
package tech.mlsql.plugins.ets
import org.apache.spark.ml.param.{IntParam, Param, StringArrayParam}
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.mlsql.session.MLSQLException
import org.apache.spark.sql.{DataFrame, SparkSession, functions => F}
import streaming.dsl.auth.TableAuthResult
import streaming.dsl.mmlib._
import streaming.dsl.mmlib.algs.param.WowParams
import tech.mlsql.common.form._
import tech.mlsql.dsl.auth.ETAuth
import tech.mlsql.dsl.auth.dsl.mmlib.ETMethod.ETMethod
import tech.mlsql.version.VersionCompatibility
class TableRepartition(override val uid: String) extends SQLAlg with VersionCompatibility with WowParams with ETAuth {
def this() = this("tech.mlsql.plugins.ets.TableRepartition")
//
override def train(df: DataFrame, path: String, params: Map[String, String]): DataFrame = {
params.get(partitionNum.name).map { item =>
set(partitionNum, item.toInt)
item
}.getOrElse {
throw new MLSQLException(s"${partitionNum.name} is required")
}
params.get(partitionType.name).map { item =>
set(partitionType, item)
item
}.getOrElse {
set(partitionType, "hash")
}
params.get(partitionCols.name).map { item =>
set(partitionCols, item.split(","))
item
}.getOrElse {
set(partitionCols, Array[String]())
}
$(partitionType) match {
case "range" =>
require(params.contains(partitionCols.name), "At least one partition-by expression must be specified.")
df.repartitionByRange($(partitionNum), $(partitionCols).map(name => F.col(name)): _*)
case _ =>
df.repartition($(partitionNum))
}
}
override def auth(etMethod: ETMethod, path: String, params: Map[String, String]): List[TableAuthResult] = {
List()
}
override def supportedVersions: Seq[String] = {
Seq("1.5.0-SNAPSHOT", "1.5.0", "1.6.0-SNAPSHOT", "1.6.0")
}
override def doc: Doc = Doc(MarkDownDoc,
s"""
|
""".stripMargin)
override def codeExample: Code = Code(SQLCode,
"""
|
""".stripMargin)
override def batchPredict(df: DataFrame, path: String, params: Map[String, String]): DataFrame = train(df, path, params)
override def load(sparkSession: SparkSession, path: String, params: Map[String, String]): Any = ???
override def predict(sparkSession: SparkSession, _model: Any, name: String, params: Map[String, String]): UserDefinedFunction = ???
final val partitionNum: IntParam = new IntParam(this, "partitionNum",
FormParams.toJson(Text(
name = "partitionNum",
value = "",
extra = Extra(
"""
|Split table into target partition num.
|""".stripMargin, label = "", options = Map(
"valueType" -> "int"
)))
))
final val partitionType: Param[String] = new Param[String](this, "partitionType",
FormParams.toJson(Select(
name = "partitionType",
values = List(),
extra = Extra(
"""
|
|""".stripMargin, label = "", options = Map(
)), valueProvider = Option(() => {
List(
KV(Option("partitionType"), Option("range")),
KV(Option("partitionType"), Option("hash"))
)
})
)
))
final val partitionCols: StringArrayParam = new StringArrayParam(this, "partitionCols",
FormParams.toJson(Dynamic(
name = "partitionCols",
extra = Extra(
"""
|
|""".stripMargin, label = "", options = Map(
"valueType" -> "array[string]"
)),
subTpe = "Select",
depends = List("partitionType"),
valueProviderName =
"""
|set partitionType="" where type="defaultParam";
|!if ''' :partitionType == "hash" ''';
|!then;
| select true as enabled as result;
|!else;
| select false as enabled as result;
|!fi;
|select * from result as output;
|""".stripMargin
)
))
override def explainParams(sparkSession: SparkSession): DataFrame = _explainParams(sparkSession)
}字段控制多组参数
比如 ET Discretizer, 他有一个method参数,该参数是枚举,有两个值,分别是buckeizer 和 quantile。 每个枚举值都关联了一组参数。 此时我们采用如下方式来做关联:
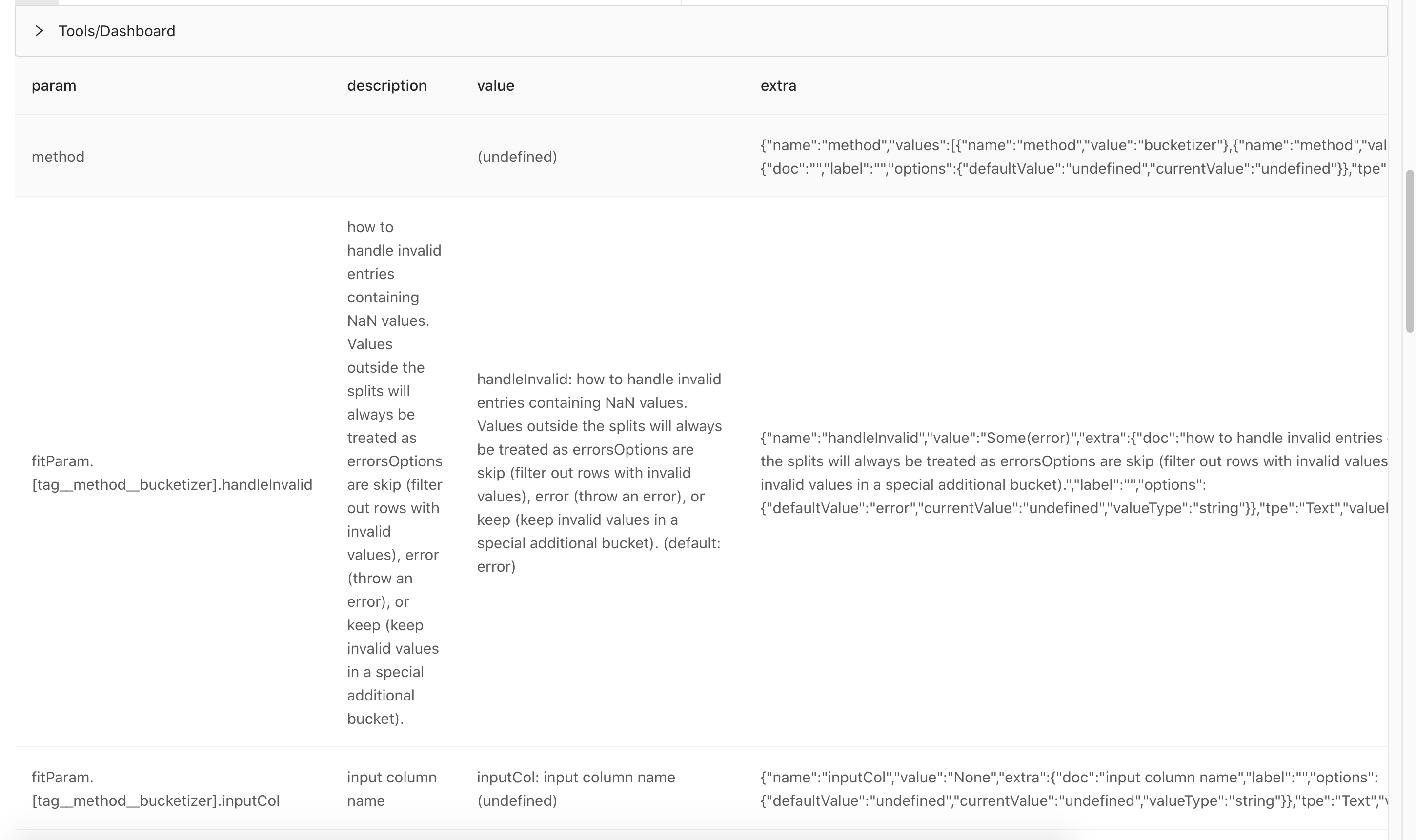
我们可以看到,现在 fitParam后面接的不再是group了,而是 tag__method__xxxx. 其中。 tag表示这个参数数据标签参数,该参数依赖于 method, 当method 对应的值为xxx时才显示。
实现代码如下:
override def explainParams(sparkSession: SparkSession): DataFrame = {
_explainTagParams(sparkSession, () => {
Map(
TagParamName(method.name, DiscretizerFeature.BUCKETIZER_METHOD) -> new Bucketizer(),
TagParamName(method.name, DiscretizerFeature.QUANTILE_METHOD) -> new QuantileDiscretizer()
)
})
}
val method:Param[String] = new Param[String](this, "method", FormParams.toJson(
Select(
name = "method",
values = List(),
extra = Extra(
doc = "",
label = "",
options = Map(
)), valueProvider = Option(() => {
List(
KV(Some("method"), Some(DiscretizerFeature.BUCKETIZER_METHOD)),
KV(Some("method"), Some(DiscretizerFeature.QUANTILE_METHOD))
)
})
)
))对于AutoML,则完全采用相同的技巧即可。但有一点不同的是,在Discretizer中,method是枚举互斥的,而在AutoML中,里面的值则是多选的。这个是前端实现时需要考虑的。
显示DataSource所有参数
MLSQL 使用 load/save 加载和保存数据。比如我们希望把数据保存成csv,那么我们肯定是需要查看保存过程中有哪些参数可用。可以使用如下命令:
!show datasources/params/csv;
格式和ET 完全一致。唯一有区别的地方在于, 以codec 为例:
{
"name": "codec",
"values": [
{
"name": "codec",
"value": "bzip2"
},
{
"name": "codec",
"value": "gzip"
},
{
"name": "codec",
"value": "lz4"
},
{
"name": "codec",
"value": "snappy"
}
],
"extra": {
"doc": "\nFor save; compression codec to use when saving to file.\nShould be the fully qualified name of a class implementing org.apache.hadoop.io.compress.CompressionCodec\nor one of case-insensitive shorten names (bzip2, gzip, lz4, and snappy). Defaults to no compression when a codec is not specified.\n",
"label": "",
"options": {
"stage": "save",
"defaultValue": "undefined",
"currentValue": "undefined",
"valueType":"String"
}
},
"tpe": "Select",
"valueProvider": {}
}可以看到,extra.options里多个一个参数stage, stage 表名该参数仅用于save语法。 此外,虽然这是一个单选框,但是默认值是undefiend,意味着前端需要保证如果用户没有选择,那么不要传递该参数。

无需安装部署,在线快速体验 Byzer
更多推荐
 0
0 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)